数据库-JDBC 任务创建指南
本页目录
数据库-JDBC 任务创建指南#
本章节介绍如何创建以 JDBC 模式抽取源数据库的任务,以及注意事项。
我们以 Oracle 作为源,OushuDB 作为目标举例。其他关系型数据库 JDBC 抽取也可以参照此文章。
前提#
已添加 Oracle 数据源,保证数据源的连通性,访问用户有必要权限。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
已创建好 Flink 集群并且状态是运行中。
任务创建流程#
选择数据源
选择一个 Oracle 数据源。

选择任务模式为“批量模式”。
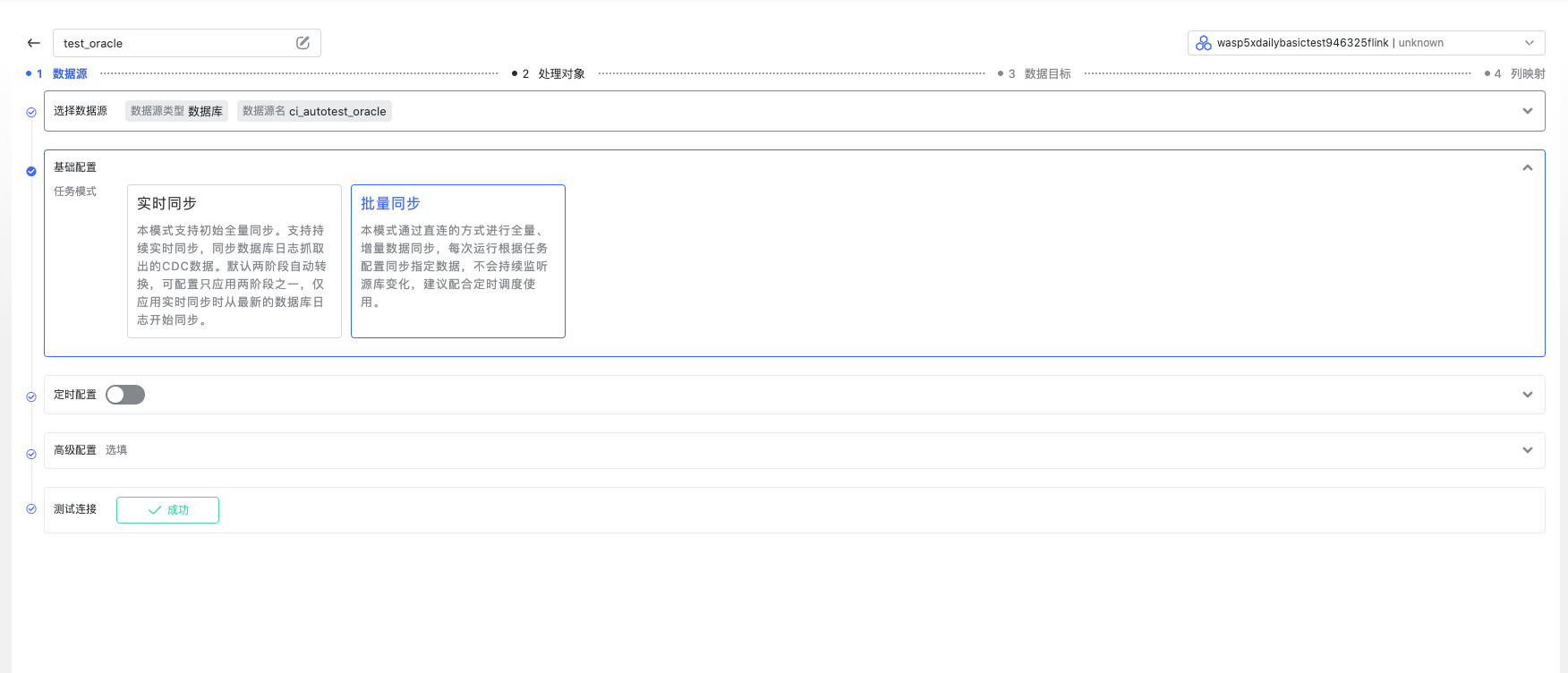
定时配置
通常 JDBC 批量抽取的场景,我们往往需要结合定时调度完成场景。Wasp 支持时间间隔和 cron 表达式两种定时方式,这里按需配置就好。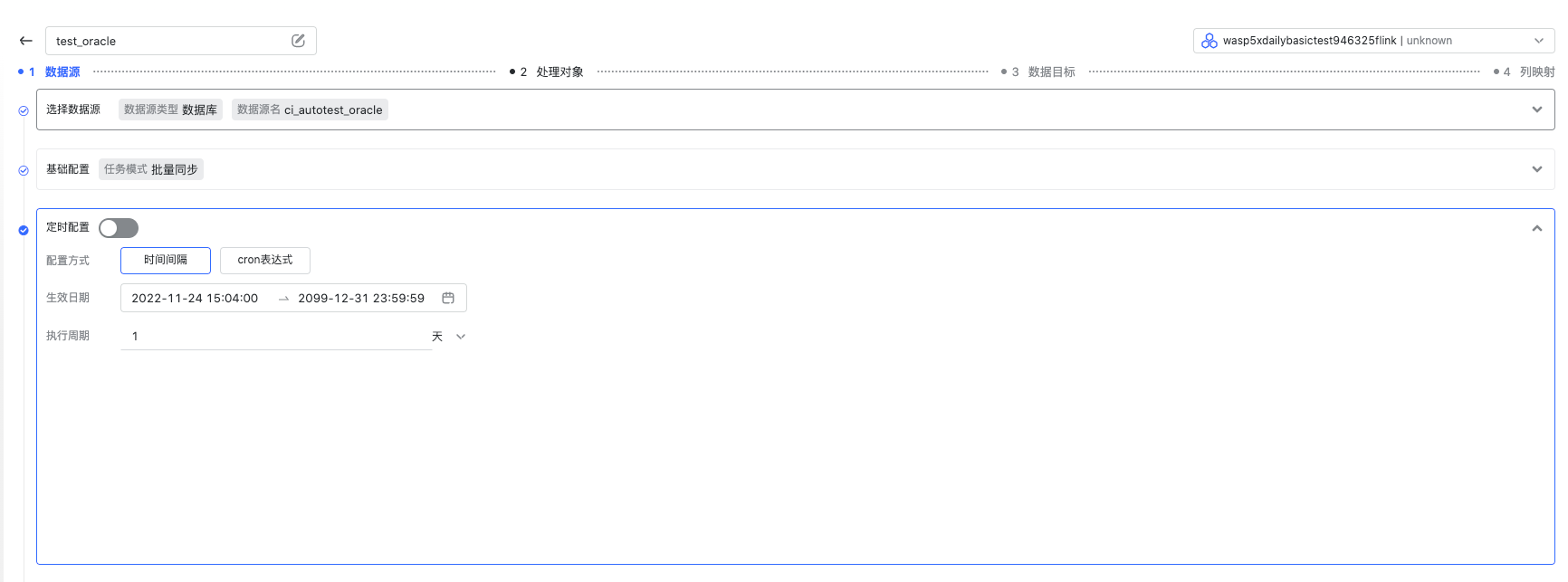
高级配置
目前批量模式中只有并行度的配置,建议根据具体场景配置,数据量、吞吐量、Flink 集群可用 slot 数等。测试连接成功后,进行下一步。
选择处理对象 根据您的业务需要,您可以选择多个 schema 下的多张表进行 JDBC 同步。
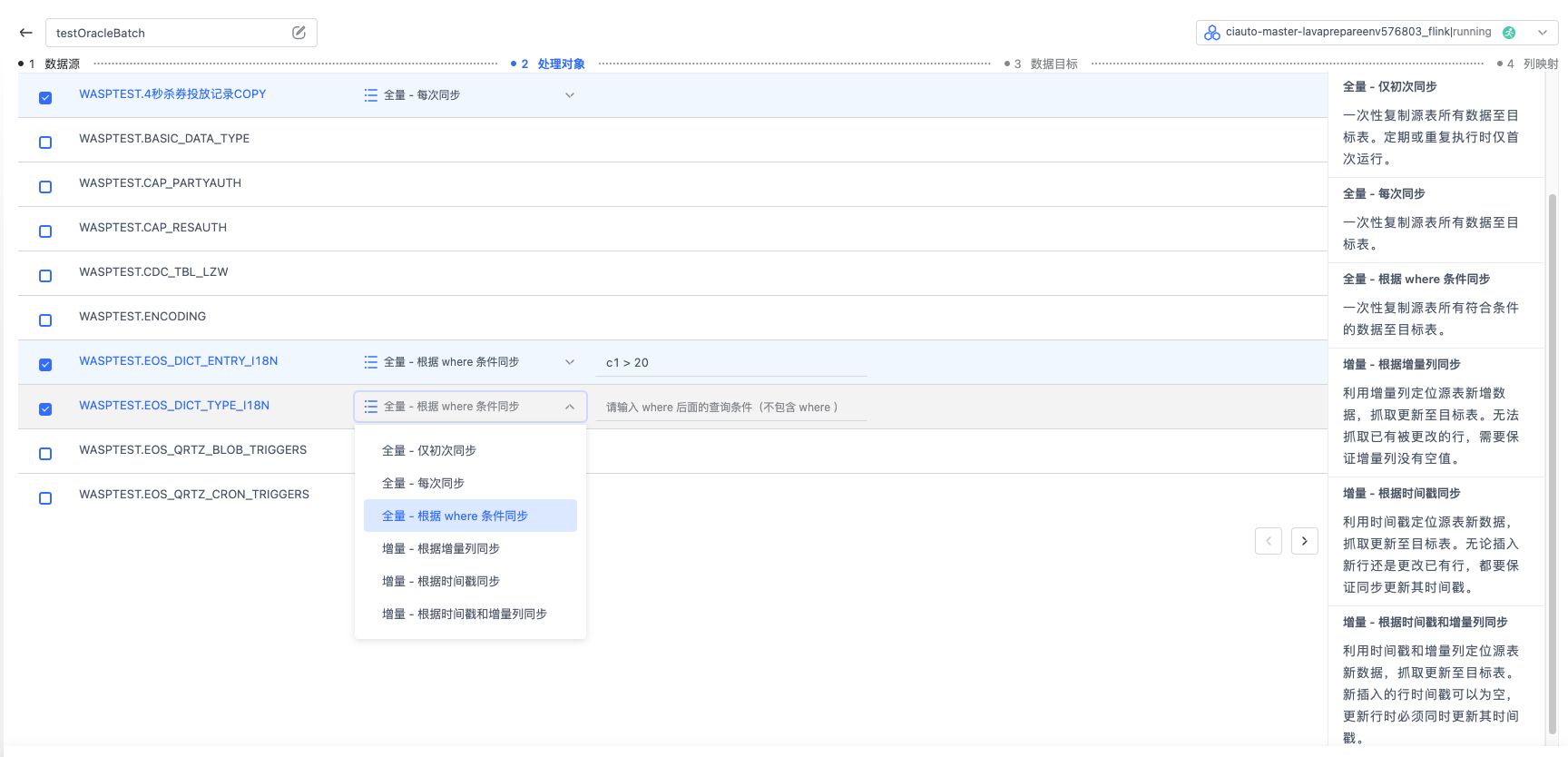 对于不同的表,您可以选择不同的同步方式,全量(每次同步),全量(仅初次同步),增量(根据时间戳同步),
增量(根据增量列同步),增量(根据时间戳和增量列同步),具体介绍可以查看产品界面右侧的文档。
对于不同的表,您可以选择不同的同步方式,全量(每次同步),全量(仅初次同步),增量(根据时间戳同步),
增量(根据增量列同步),增量(根据时间戳和增量列同步),具体介绍可以查看产品界面右侧的文档。选择数据目标
选择一个 OushuDB 数据目标。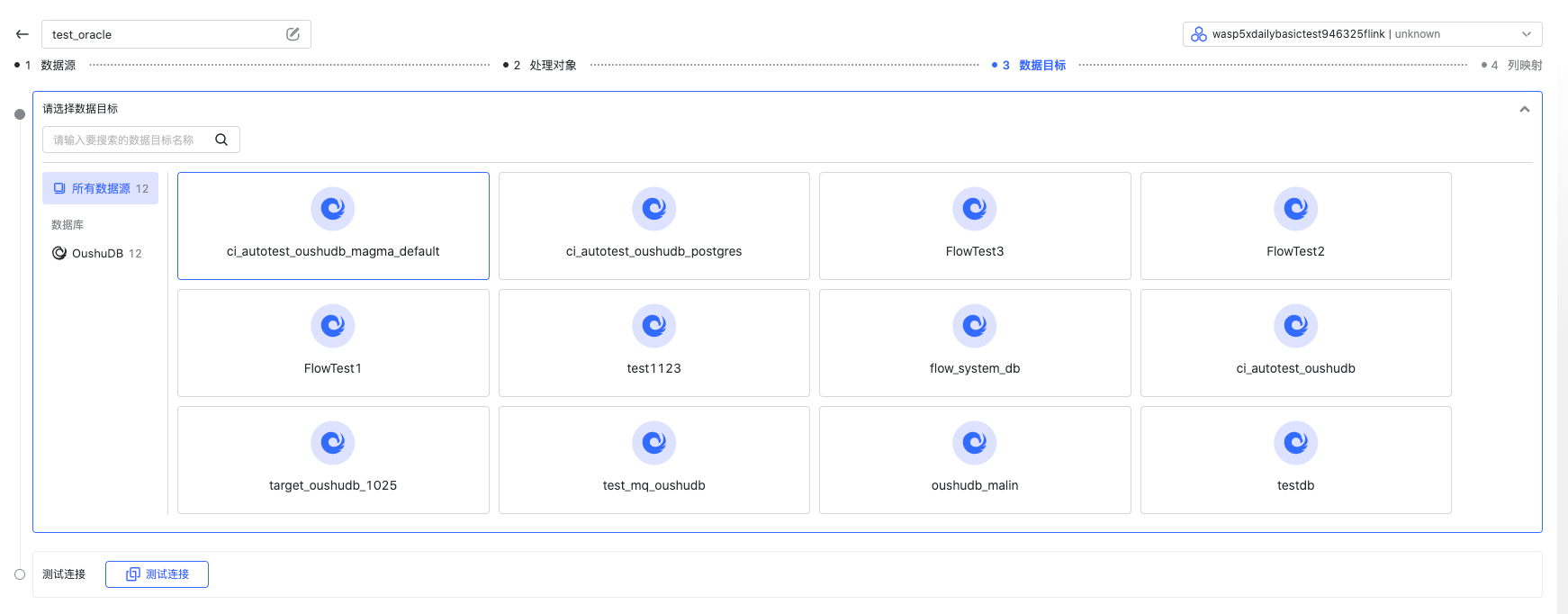
配置列映射
在这里,您可以指定某张源表要导入到某张目标表,是否是已有表/自动建表等,点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Oracle 通过 JDBC 批量的方式抽取并导入到 OushuDB 的数据集成任务就创建完成了。