数据集成任务创建指南
本页目录
数据集成任务创建指南#
数据库-CDC 任务创建指南#
本章节介绍如何创建以 CDC 模式抽取源数据库的任务,以及注意事项。
我们以 Oracle 作为源,OushuDB 作为目标举例。其他数据库作为源配置 CDC 任务时,也可参考此文章,只是源库侧 CDC 的配置有些不同。
前提#
源侧开启 CDC 相关配置,详见 CDC配置指南
已添加 Oracle 数据源,保证数据源的连通性,访问用户有必要权限。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
Wasp 侧需要保证,已创建好 Flink 集群并且状态是运行中。
任务创建流程#
选择数据源
选择一个 Oracle 数据源。

选择任务模式为“实时模式”。

高级配置选择同步历史。
并行度建议根据具体场景配置,数据量、TPS 要求、Flink 集群可用 slot 数等。 更新频率其实是 Flink checkpoint 的间隔,每次 checkpoint,我们会向目标数据库提交一次。当然,OushuDB 作为目标时,我们做了一些优化,满足一定 batch 时就会提交,所以通常这个配置项可配置成您能接收的最大延迟。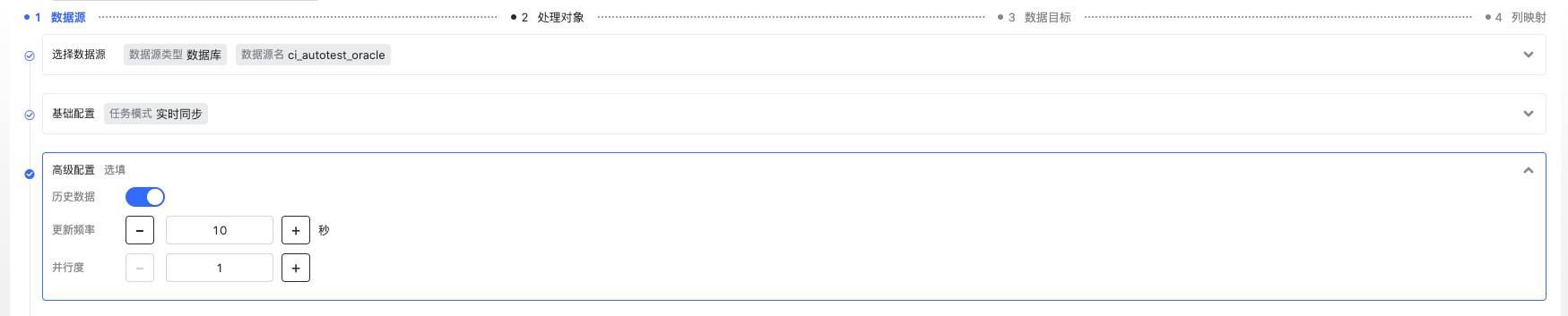
测试连接成功后,进行下一步。
选择处理对象
根据您的业务需要,您可以选择多个 schema 下的多张表进行 CDC 同步。
选择数据目标
选择一个 OushuDB 数据目标。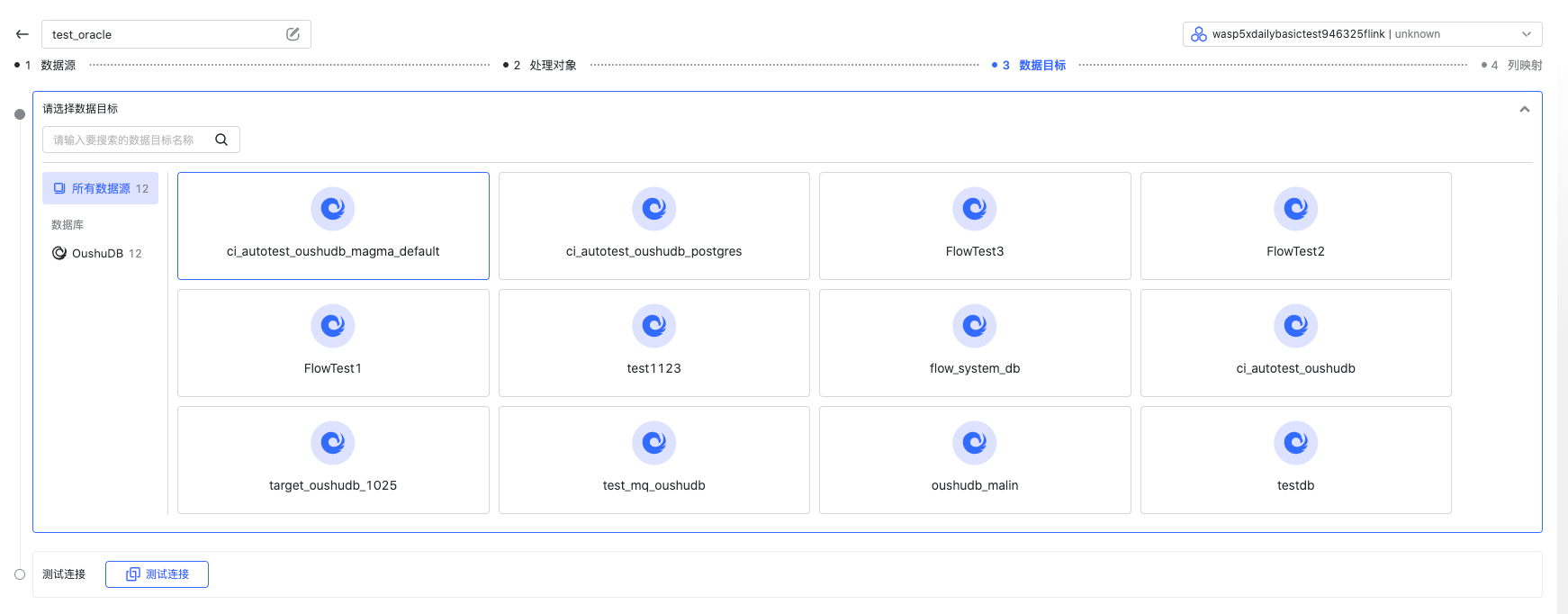
配置列映射
在这里,您可以指定某张源表要导入到某张目标表,是否是已有表/自动建表等,点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Oracle 通过实时 CDC 的方式抽取并导入到 OushuDB 的数据集成任务就创建完成了。
数据库-JDBC 任务创建指南#
本章节介绍如何创建以 JDBC 模式抽取源数据库的任务,以及注意事项。
我们以 Oracle 作为源,OushuDB 作为目标举例。其他关系型数据库 JDBC 抽取也可以参照此文章。
前提#
已添加 Oracle 数据源,保证数据源的连通性,访问用户有必要权限。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
已创建好 Flink 集群并且状态是运行中。
任务创建流程#
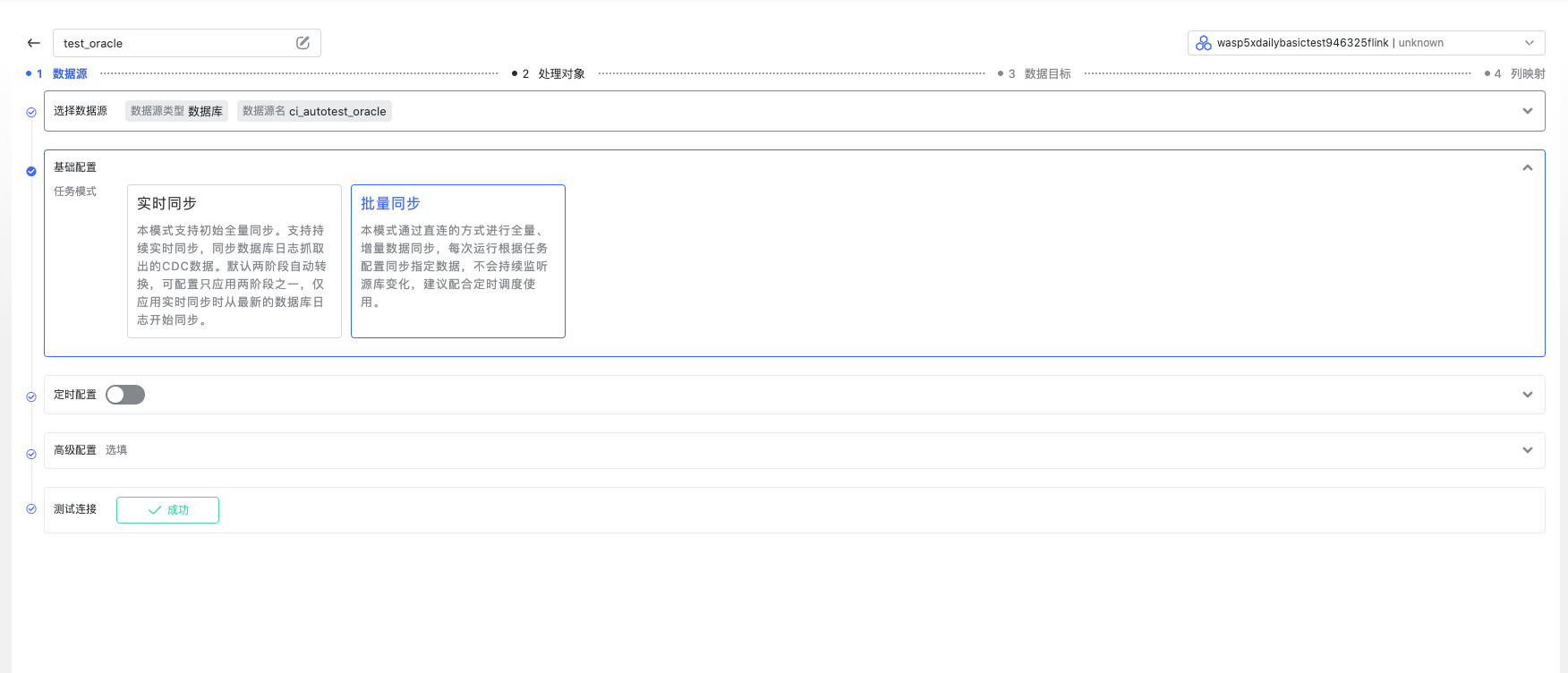
选择数据源
选择一个 Oracle 数据源。
选择任务模式为“批量模式”。
定时配置
通常 JDBC 批量抽取的场景,我们往往需要结合定时调度完成场景。Wasp 支持时间间隔和 cron 表达式两种定时方式,这里按需配置就好。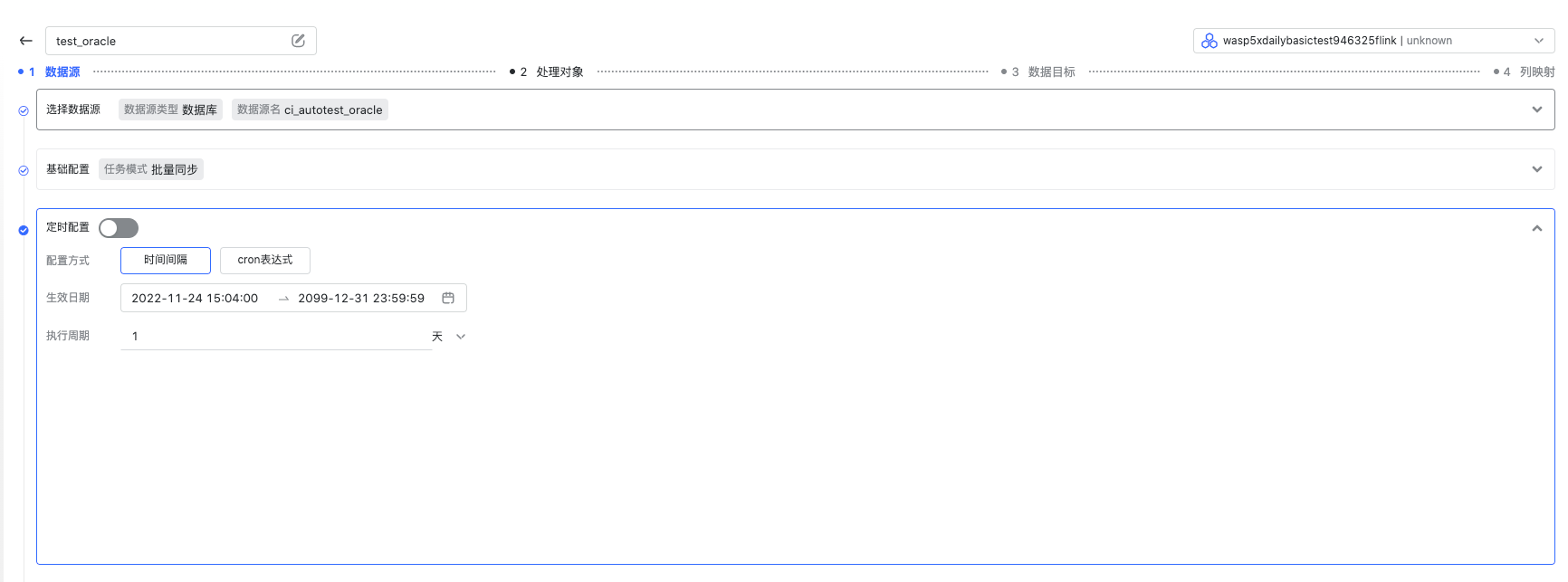
高级配置
目前批量模式中只有并行度的配置,建议根据具体场景配置,数据量、吞吐量、Flink 集群可用 slot 数等。测试连接成功后,进行下一步。
选择处理对象 根据您的业务需要,您可以选择多个 schema 下的多张表进行 JDBC 同步。
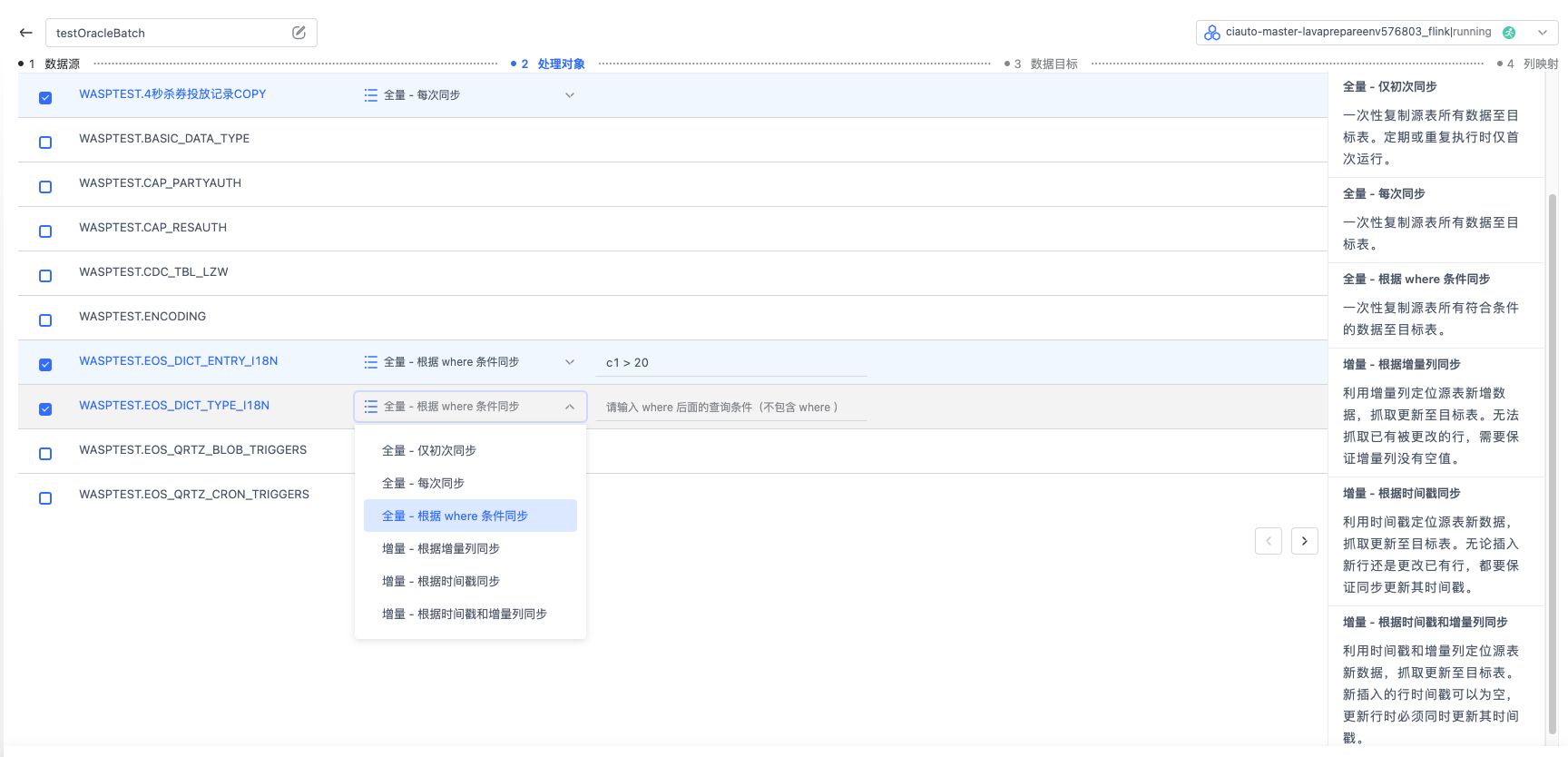 对于不同的表,您可以选择不同的同步方式,全量(每次同步),全量(仅初次同步),全量(根据 where 条件同步,支持时间宏语法,详见 时间宏配置),增量(根据时间戳同步),
增量(根据增量列同步),增量(根据时间戳和增量列同步),具体介绍可以查看产品界面右侧的文档。
对于不同的表,您可以选择不同的同步方式,全量(每次同步),全量(仅初次同步),全量(根据 where 条件同步,支持时间宏语法,详见 时间宏配置),增量(根据时间戳同步),
增量(根据增量列同步),增量(根据时间戳和增量列同步),具体介绍可以查看产品界面右侧的文档。选择数据目标
选择一个 OushuDB 数据目标。配置列映射
在这里,您可以指定某张源表要导入到某张目标表,是否是已有表/自动建表等,点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Oracle 通过 JDBC 批量的方式抽取并导入到 OushuDB 的数据集成任务就创建完成了。
Kafka-CDC 任务创建指南#
本章节介绍如何创建 Kafka CDC 模式抽取源数据库的任务,以及注意事项。
任务创建流程#
首先选择 Kafka 数据源
接着选择模式,这里我们选择 CDC 模式
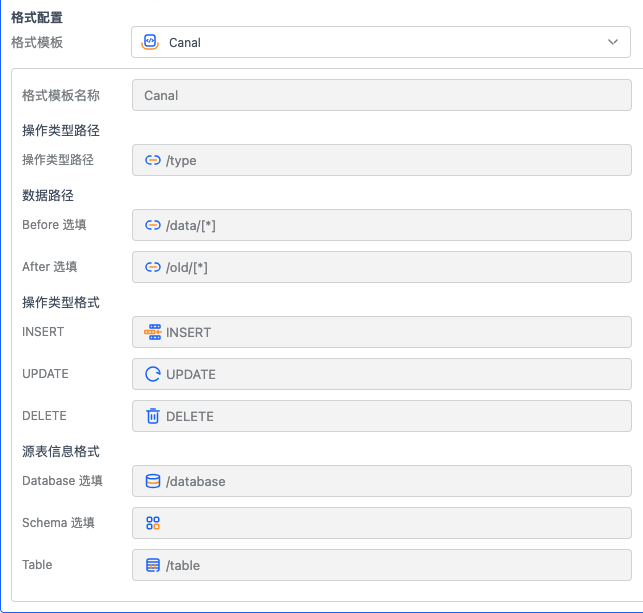
选中 CDC 模式的话,在高级配置中需要填写CDC相关的配置信息,这里默认提供了CDC的常用模板,如Ogg,Canal,腾讯数据订阅,也可以自定义配置模板
这里我们以下面这条Canal的 CDC JSON 数据举例
{
"data": [
{
"id": "111",
"name": "scooter",
"description": "Big 2-wheel scooter",
"weight": "5.18"
}
],
"database": "inventory",
"es": 1589373560000,
"id": 9,
"isDdl": false,
"mysqlType": {
"id": "INTEGER",
"name": "VARCHAR(255)",
"description": "VARCHAR(512)",
"weight": "FLOAT"
},
"old": [
{
"weight": "5.15"
}
],
"pkNames": [
"id"
],
"sql": "",
"sqlType": {
"id": 4,
"name": 12,
"description": 12,
"weight": 7
},
"table": "products",
"ts": 1589373560798,
"type": "UPDATE"
}
操作类型路径是描述 JSON 数据中,操作类型的 JsonPath,如样例中格式,则填写
/type操作类型格式是描述这段 CDC 数据的操作和对应的值,根据’type’字段中的值对应
INSERT:INSERT
UPDATE:UPDATE
DELETE:DELETE源表信息格式,是用来描述这条 CDC 数据来自哪张表,这里填写对应的 JsonPath,表名需要是全限定表名称,比如db1.schema2.table3,如样例中的 Canal CDC 数据,全限定表名是由字段 ‘table’ 和 ‘database’ 两个字段组成,源表信息格式处需要填写上 Database 和 Table 的 JsonPath,这样在 CDC 数据从 Kafka 中消费出来时,才能解析出它是来自哪一张源表,根据样例数据对应字段值,我们能知道这条 CDC 数据是来自 inventory.products 表。
测试连接通过后进入到下一步选择处理对象
选择处理对象
这里分为两个步骤选择 topic,表示从哪些 topic 中获取数据
添加元数据映射(元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节)元数据是用来描述表的结构,即我们用哪种表结构来解析这条数据,数据源使用手册中已经介绍过元数据的定义和使用,由于 CDC 元数据定义会有特殊,这里再额外补充上。
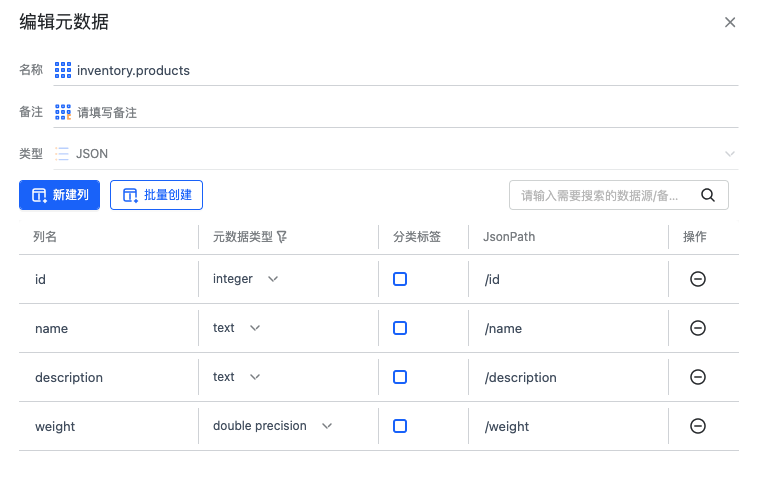
对于Kafka Upsert 模式和 无Before/After 的 CDC 数据,元数据定义 JsonPath 时我们需要传递完整的 Path 路径。
但对于有 Before 和 After 的CDC数据来说,如上面 Canal 的样例数据,在 /data 和 /old 中都会出现源表的列,这样我们在定义元数据时,只需要定义 After 和 Before 字段下的子 JsonPath ,这样再加上配置模版时 Before 和 After 的数据路径我们能得到完整的 JsonPath。
对于 TENCENT_DATA 这种格式,只需要定义列名和类型,无需定义 JsonPath,Wasp 内部处理时会根据 Json 中的 columns 字段自动识别 JsonPath。
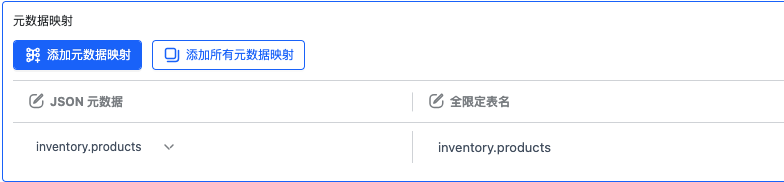
此外,对于 CDC 元数据创建时,名称建议创建为全限定表名,方便快速添加。
先选择需要消费的 Topic
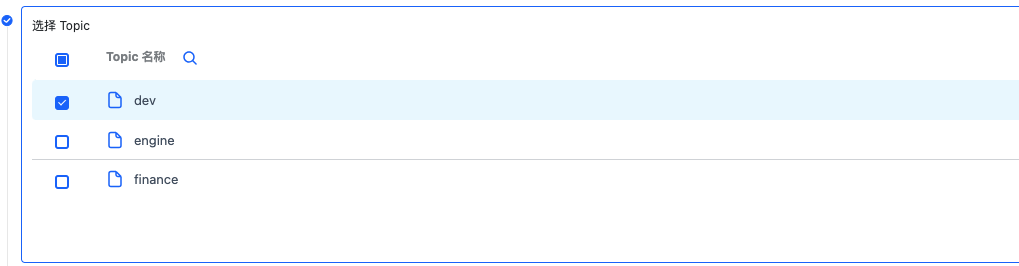
接着选择元数据后并填写对应的全限定表名,表示这个元数据和哪张源表关联上
选择数据目标 选择一个 OushuDB 数据目标。
配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Kafka CDC 的方式抽取并导入到 OushuDB 的数据集成任务就创建完成了。
Kafka-upsert 任务创建指南#
本章节介绍如何创建抽取 Kafka 数据,按照 CSV/JSON 格式解析后 upsert 到 OushuDB 的任务。
前提#
已添加 Kafka 数据源,保证数据源的连通性。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
任务创建流程#
创建元数据
在数据源模块编辑已添加的 Kafka 数据源,添加元数据。元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节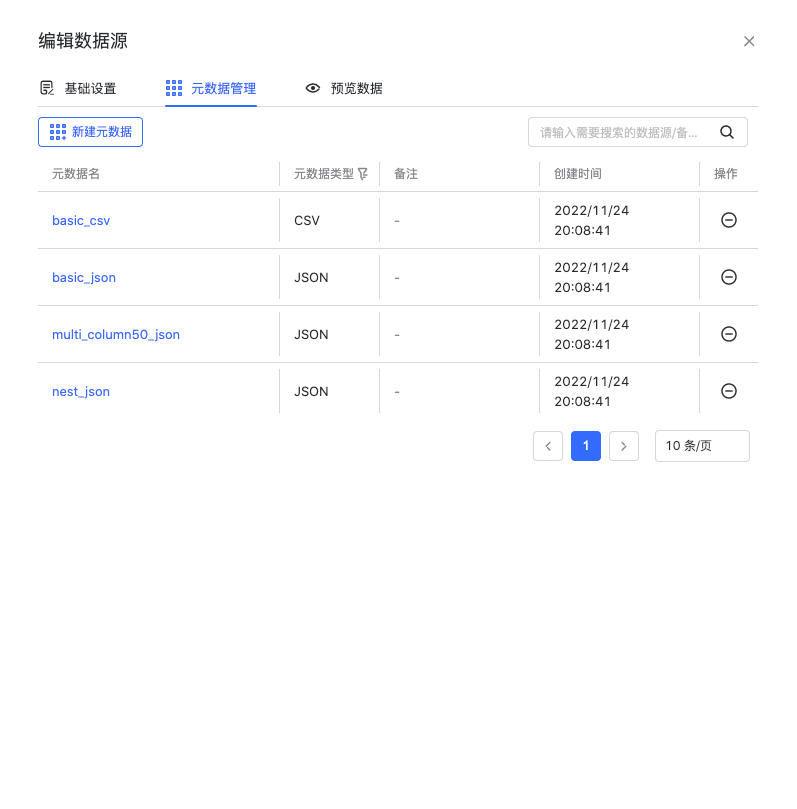
选择数据源
接着选择模式,这里我们选择 upsert 模式 测试连接通过后进入到下一步选择处理对象选择处理对象
这里每个 topic 对应一个元数据,选中 topic 后需要选择不同类型的元数据,这里支持 JSON 和 CSV 类型的元数据。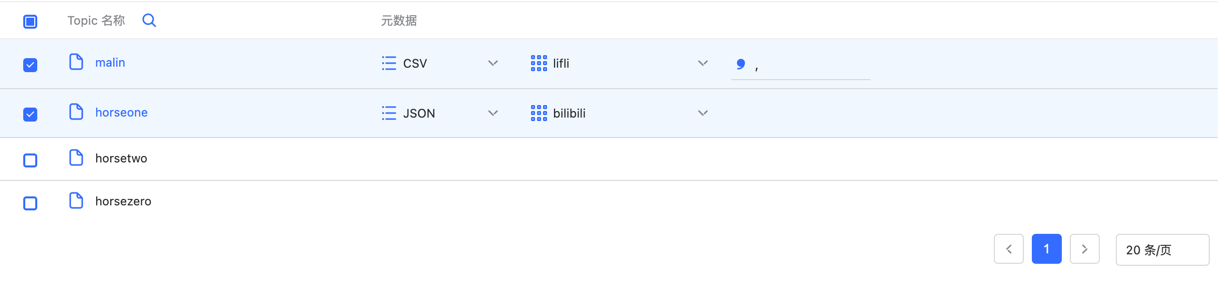 值得注意的是:对于 CSV 元数据,需要填写分隔符
值得注意的是:对于 CSV 元数据,需要填写分隔符选择数据目标
选择一个 OushuDB 数据目标。配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Kafka 抽取,按照 CSV/JSON 格式解析后,upsert 导入到 OushuDB 的数据集成任务就创建完成了。
定量文件同步任务创建指南#
本章节介绍如何创建抽取定量文件,按照 CSV/JSON 格式解析后 upsert 到 OushuDB 的任务,下面用 HDFS->OushuDB 举例
前提#
已添加 HDFS 数据源,保证数据源的连通性,注意 HDFS 数据源中”工作目录”的指定,这将指定数据集成时可选的文件根目录。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
任务创建流程#
创建元数据
在数据源模块编辑已添加的 HDFS 数据源,添加元数据。元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节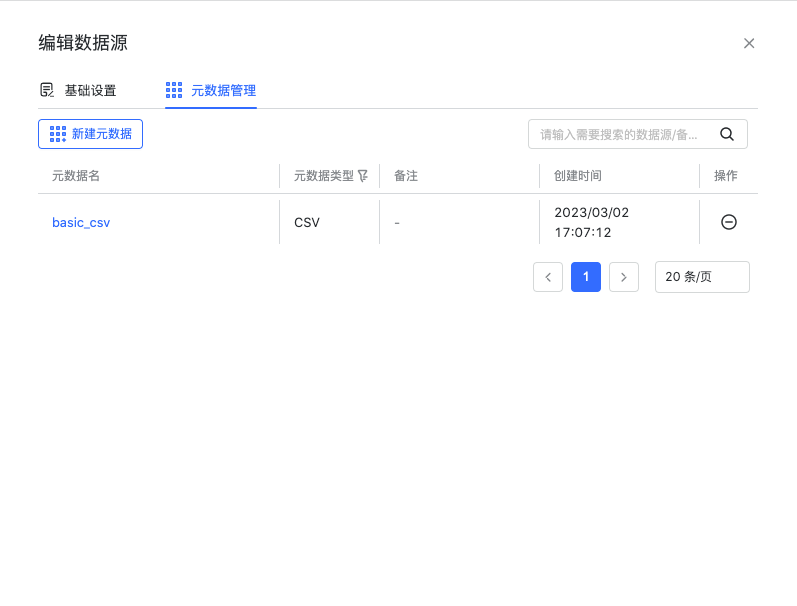
创建数据集成任务
选择数据源,接着选择模式,这里我们选择定量文件同步模式 测试连接通过后进入到下一步选择处理对象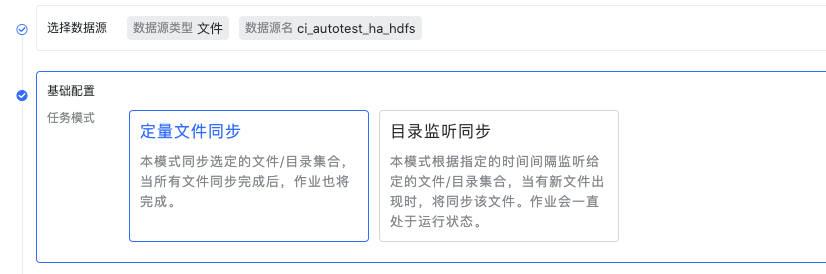
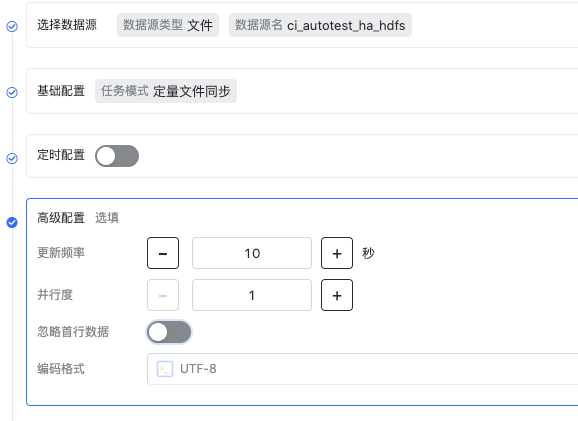
高级配置:
更新频率,影响写入目标的频率和记录 checkpoint 的频率,适当增加该值可以增加吞吐量。
并行度,即并发读取/写入。
忽略首行数据,勾选后读取每个文件时都会跳过首行。
编码格式,当前仅开放 UTF-8
选择处理对象
这里每个文件/目录对应一个元数据,勾选文件/目录后需要选择不同类型的元数据,这里支持 JSON 和 CSV 类型的元数据。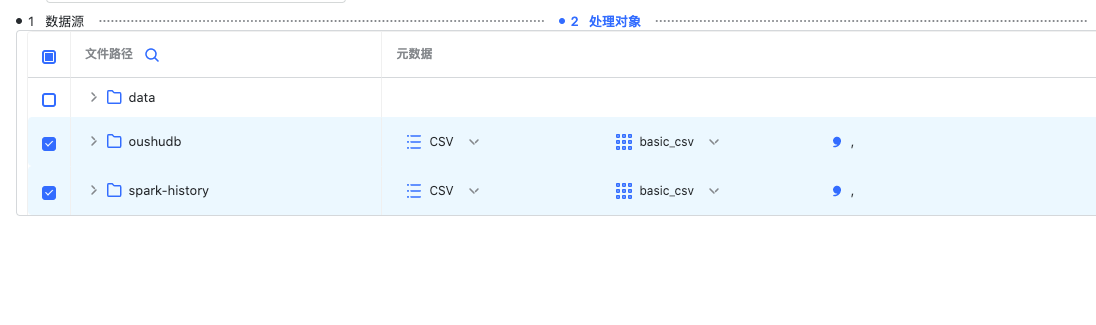 值得注意的是:对于 CSV 元数据,需要填写分隔符
值得注意的是:对于 CSV 元数据,需要填写分隔符选择数据目标
选择一个 OushuDB 数据目标。配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 HDFS 抽取,按照 CSV/JSON 格式解析后,upsert 导入到 OushuDB 的数据集成任务就创建完成了。
目录监听同步任务创建指南#
本章节介绍如何创建监听文件目录抽取文件,按照 CSV/JSON 格式解析后 upsert 到 OushuDB 的任务,下面用 HDFS->OushuDB 举例
该模式不仅会抽取当前选中的文件/目录下的内容,还会定时扫描目录捕获新增文件并抽取。
前提#
已添加 HDFS 数据源,保证数据源的连通性,注意 HDFS 数据源中”工作目录”的指定,这将指定数据集成时可选的文件根目录。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
任务创建流程#
创建元数据
在数据源模块编辑已添加的 HDFS 数据源,添加元数据。元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节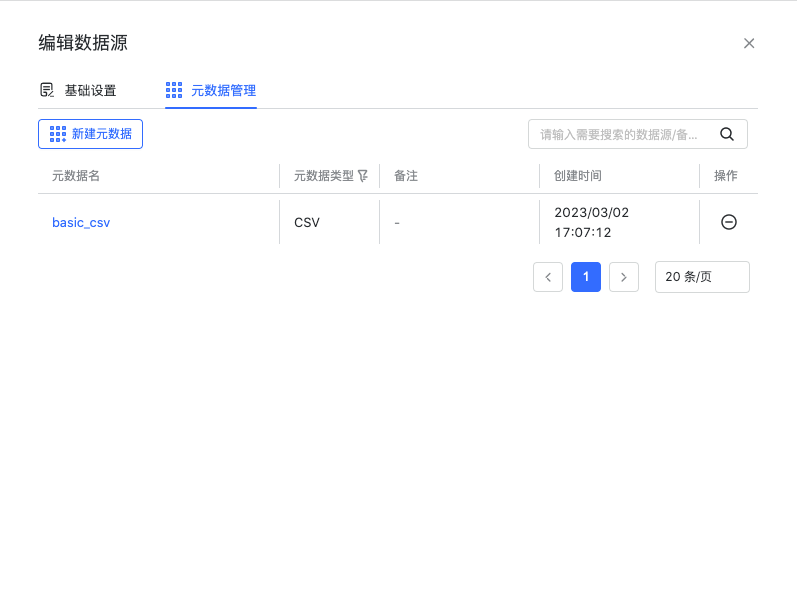
创建数据集成任务
选择数据源,接着选择模式,这里我们选择目录监听同步模式,该模式将会监听选中的目录,如果有文件新增,则会抽取该文件。在此模式下依然 可以选择文件或者目录,只是会监听目录捕获新增文件,而不能抓到文件中新增的内容。测试连接通过后进入到下一步选择处理对象
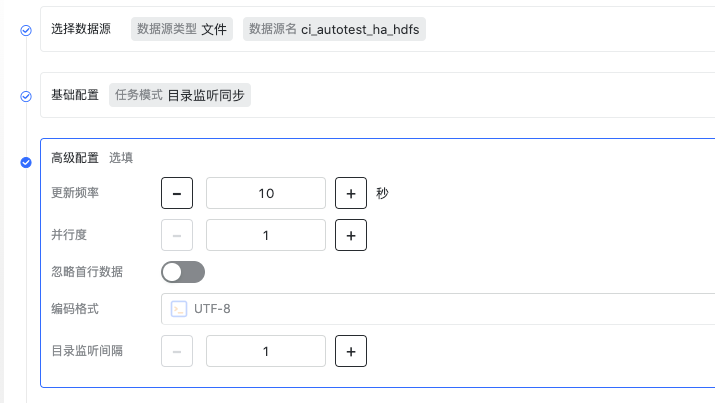
高级配置:
更新频率,影响写入目标的频率和记录 checkpoint 的频率,适当增加该值可以增加吞吐量。
并行度,即并发读取/写入。
忽略首行数据,勾选后读取每个文件时都会跳过首行。
编码格式,当前仅开放 UTF-8
目录监听间隔,配置定时监听目录的时间间隔,单位:秒。
选择处理对象
这里每个文件/目录对应一个元数据,勾选文件/目录后需要选择不同类型的元数据,这里支持 JSON 和 CSV 类型的元数据。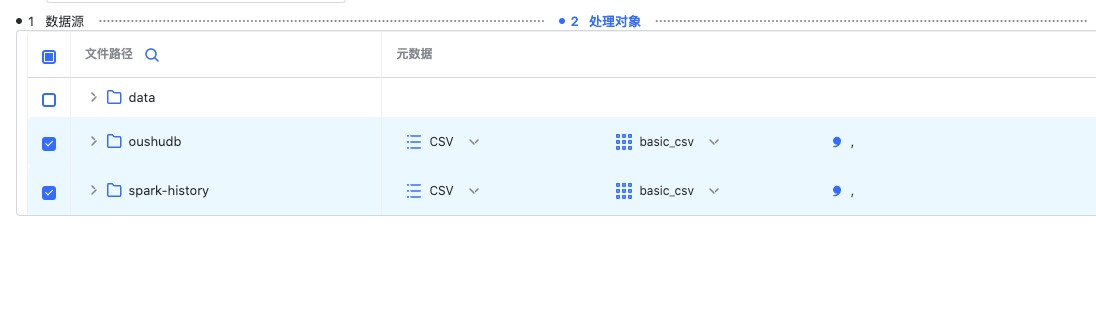 值得注意的是:对于 CSV 元数据,需要填写分隔符
值得注意的是:对于 CSV 元数据,需要填写分隔符选择数据目标
选择一个 OushuDB 数据目标。配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 HDFS 抽取,并且监听目录新增文件,按照 CSV/JSON 格式解析后,upsert 导入到 OushuDB 的数据集成任务就创建完成了。