数据加工算子指南
本页目录
数据加工算子指南#
数据加工算子创建指南#
本章节详细介绍数据加工各种算子的配置参数
kafkaSource#
kafkaSource可以作为数据加工处理数据的来源,通过在创建任务页面左侧,拖动kafka数据源中某个topic到画布中创建 ,kafka算子的输出只能连接解析算子。 可配置项有offset策略和kafka消费参数
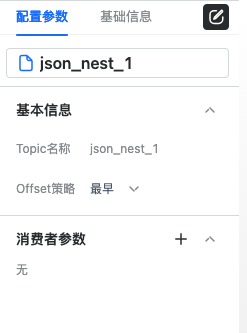
offset策略有以下四种
最早:从头开始消费全部数据
最新:只消费最新数据
已提交:从提交标记开始消费,选择此策略时需要指定重置策略,当读取不到提交标记时使用重置策略消费
时间:从某个时间点后开始消费,选择此策略需要指定一个时间点
注意:flink自带了checkpoint机制,会记录当前消费情况。所以offset策略只在首次启动任务时生效,后续再运行时,会从上一次任务运行消费到的offset后继续消费
消费者参数以key、value的形式添加,可以参考flink文档
解析#
解析算子通常连接kafkaSource的输出端,用于将无结构的kafka流数据解析成结构化的数据,便于后续处理,可配置项包括数据格式和元数据
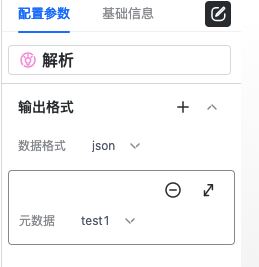
数据格式包括json和csv两种,用于表示从kafka中消费到的数据格式是json还是kafka
元数据是在数据源中创建的,用于表示从kafka中消费到的数据的结构。元数据可以配置多个,每配置一个元数据,解析算子都会有一个输出端口与之对应。 运行时,解析算子读取到kafka中的数据后,会挨个和配置的元数据做比对,比对成功后,会将数据发送到对应的输出端口
列衍生#
列衍生算子用于在原有流数据上添加一些额外数据,可以配置多个衍生规则,每个衍生规则会生成一列新的数据
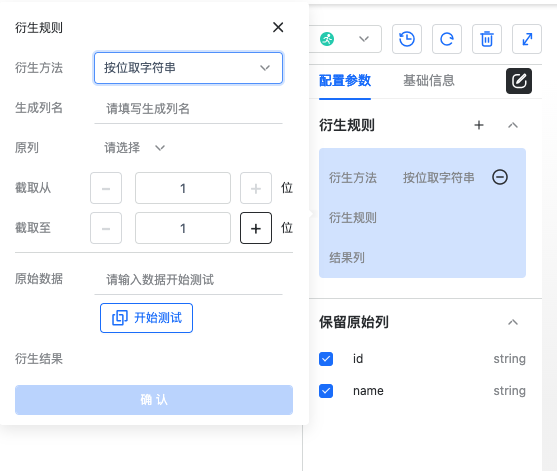
衍生规则有以下三种
按位取字符串 选择一个源列,截取其中部分值,用截取到的值生成一个新的列
正则表达式 选择一个源列,使用正则表达式匹配其中的数据,用提取到的值生成一个新的列
固定值 生成一个新列,列的值是一个固定值(由用户输入)
新建目标表#
新建目标表算子会创建一个新的oushudb表,并作为流数据的存储目标,配置项包括所属位置以及映射
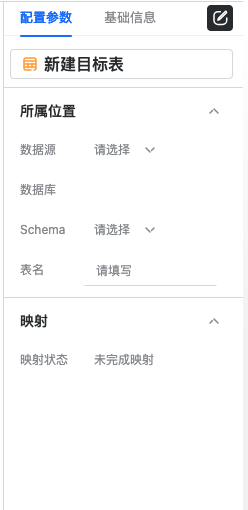
所属位置表示目标表要创建的位置,包括数据源、数据库、schema以及表名
映射用于调整源列和目标表的列之间的对应关系,数据在写入目标表时,将按照这种对应关系写入。新建目标表一般会自动完成映射,无需再手动调整。
已有表#
已有表算子通过在左侧数据源中拖入一个oushudb表来创建,或者从某个算子的输出端中拖出来算子选择,选择一个目标。
已有表是已经已经存在的表,因此相对于新建目标表算子不用再选择所属位置,只需要调整映射。
在添加已有表算子时,会自动根据列名匹配度进行映射,当源列和目标列完全匹配时,映射状态是自动映射已完成。当部分匹配或完全不匹配时,映射状态是映射未完成,需要手动调整映射。
配置映射的方法为:在算子映射区域,点击配置按钮,在打开的映射页面中勾选要修改的映射,调整源列和目标列的对应关系