查询处理流程
本页目录
查询处理流程#
OushuDB是一个并行执行引擎,下面我们来看一看OushuDB是如何并行执行前面例子中的那个查询的。我们可以看到上面的查询计划中我们在motion节点的边界处进行了slice的划分。查询计划被分为了3个slice。每个slice将会由多个线程执行。执行每个slice的线程数是N或者1,其中N是查询的并行度。
一个查询的并行度由查询的复杂度以及查询执行时系统可使用资源动态确定。通常大查询并行度高,而小查询并行度低。
在客户端通过psql,JDBC或者ODBC连接到OushuDB main节点时,main会启动一个线程,这个线程负责OushuDB与客户端的交互,接收查询,解析查询,调用优化器得到查询计划,并且派遣查询到segment中执行。我们称该线程为QD(Query Dispatch)线程。在Segment上启动并真正负责执行查询的线程我们称之为QE(Query Execution)线程。
假设该查询的并行度N为2,OushuDB会启动2个virtual segment去执行这个查询。virtual segment可以看做是一个资源的容器。比如一个virtual segment可以使用1G内存和2个virtual core。针对每一个virtual segment,OushuDB会对查询计划中每一个slice启动一个QE(Query Execution)线程。注:顶层带gather motion的slice除外,顶层带gather motion的slice会复用QD线程。一个slice在所有virtual segment上的线程集合我们称为一个gang。根据gang里面线程的个数,我们有两种gang:N-gang和1-gang。下图给出了查询在使用两个virtual segment执行时的示意图。
注: #veg 标识vseg的数量,参考 计数符号 。
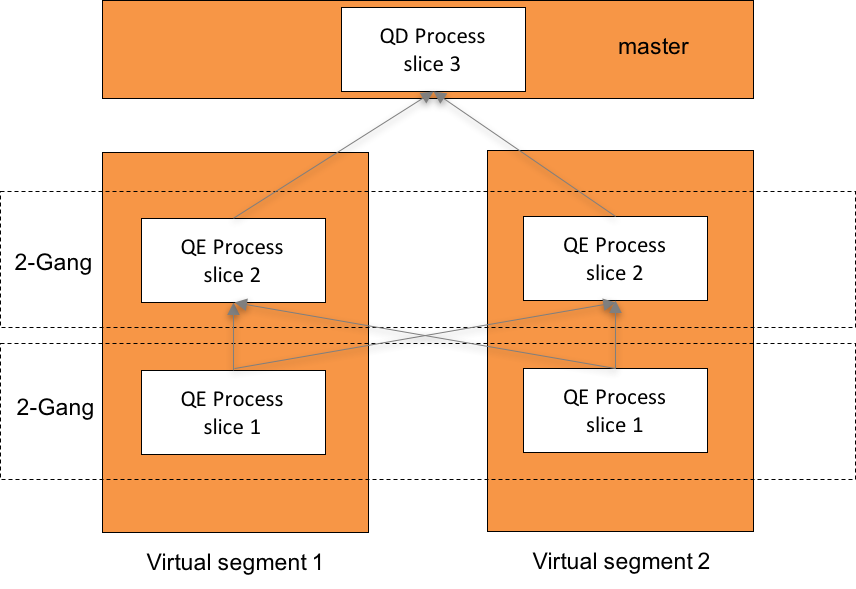
图2. 查询执行线程
查询并行度 (只为高级用户阅读)#
OushuDB6中, 每个物理节点的VSeg数量由 nvseg_perseg 统一控制。
一个查询会启动多少个 virtual segment,即查询的并行度是多少是由以下因素决定的。通常用户使用 OushuDB 并不需要知道 OushuDB 如何分配 Virtual Segment 的细节。OushuDB 会自动优化选择并行度。
查询的代价:小查询OushuDB会使用少量的virtual segment,大查询OushuDB使用的virtual segment数会多一些。
查询执行时可使用的资源:如果在查询执行时可以使用的资源比较多的话,OushuDB会使用更多的virtual segment。
Hash分布的表:如果查询里面全部为hash分布的表且所有hash分布的表都具有相同的bucket number N,则会使用N个virtual segment。如果hash分布的表的bucket number不同的话,会使用所有表中最大的bucket number个virtual segment。如果查询里面既有hash分布的表,又有random分布的表,如果所有random分布的表的总大小小于或者等于所有hash分布表的大小的1.5倍,则使用hash分布表的bucket number个virtual segment。否则的话,会把hash分布的表做为random分布的表处理。
查询的类型:如果查询里面包含用户自定义函数或者有外部表的话,使用的virtual segment个数由 VC 属性 max_nvseg_perquery 和 max_nvseg_perquery_perseg 参数以及外部表的ON子句中数字和location列表确定。如果一个查询的结果是一个hash分布的表,则使用的virtual segment数一定是该表的bucket数。
更加具体的规则如下:
VC 属性 enforce_nvseg 默认值为0,设置为非0时可以强制#vseg (virtual segment数)
查询中只有Random分布的表:#vseg依赖于表的大小。一个HDFS block分配一个vseg,默认大小为128M,数量受 VC 属性 max_nvseg_perquery 和 max_nvseg_perquery_perseg 限制
查询中只有Hash分布的表: #vseg由表的最大bucket数决定,bucketnum存储在gp_distribution_policy
Random分布和hash分布的表共存:如果所有random分布的表的总大小小于或者等于所有hash分布表的大小的1.5倍,则使用hash分布表的bucket number个virtual segment。否则的话,会把hash分布的表做为random分布的表处理。
查询中存在UDF(User-defined functions): #vseg 由 VC 属性 max_nvseg_perquery 和 max_nvseg_perquery_perseg 确定。
查询中存在gpfdist外部表: #vseg至少为location列表中的location个数
CREATE EXTERNAL TABLE: #vseg为ON子句中的数字
Hash分布的表被拷贝到文件或者从文件拷贝: #vseg由该表的bucket数确定
Random分布的表被拷贝到文件:#vseg由表的大小确定
拷贝文件中数据到Random分布的表:#vseg为6
ANALYZE表: 通常分析非分区的表会使用比等量分区表更多的#vseg数
查询使用内存量 (只为高级用户阅读)#
OushuDB6中, 每个物理节点的对于单个查询的内存总用量限制由 statement_mem 统一控制。
一个查询启动的每一个virtual segment都有固定的内存额度,plantree中所有的操作符共享该额度。操作符分为memory intensive和non memory intensive两类,对于每一个non memory intensive的操作符默认分配100KB内存,剩余的内存量由memory intensive的操作符均分。对于memory intensive的操作符如果没有足够的内存,该操作会使用溢出文件(spill files)。相比于完全在内存中执行的操作,磁盘溢出文件会慢得多。
memory intensive的操作符包括Material, Hash, Sort, Window, ShareInputScan, BitmapIndexScan, FunctionScan和TableFunctionScan。对于某些Agg操作如果是hash策略或者包含DQA及排序操作,以及包含function call的Result操作也属于这个类别。
statement memory的默认值为256MB,即每一个virtual segment内存额度
hawq_rm_memory_limit_perseg限制一个物理segment执行允许的最大内存量,默认为64GB
当 VC 属性 enforce_nvseg 非0时,可以通过 enforce_memory_pervseg 更改每一个vseg的内存额度
可以通过资源队列配置vseg的内存额度,该信息保存在系统表pg_resqueue