Kafka-CDC 任务创建指南
本页目录
Kafka-CDC 任务创建指南#
本章节介绍如何创建 Kafka CDC 模式抽取源数据库的任务,以及注意事项。
任务创建流程#
首先选择 Kafka 数据源
接着选择模式,这里我们选择 CDC 模式 选中 CDC 模式的话,在高级配置中需要填写这些关键信息
选中 CDC 模式的话,在高级配置中需要填写这些关键信息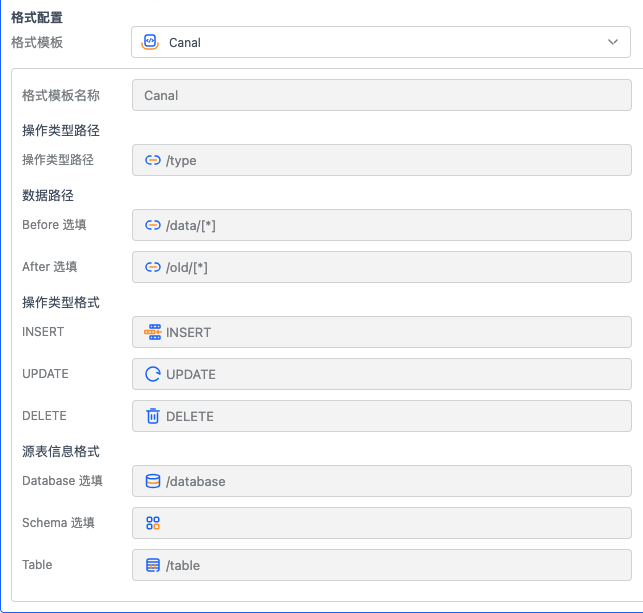
这里我们看一下面这串 CDC JSON 数据举例
{
"id": 1,
"table":"oushu.public.table1",
"op": "insert",
"ts_ms": 1589362330904,
"record":{
"pkid":1,
"name": "uzi",
"description": "weapon",
}
}
{
"id": 2,
"table":"oushu.public.table1",
"op": "update",
"ts_ms": 1589362331234,
"record":{
"pkid":1,
"name": "ak47",
"description": "weapon",
}
}
{
"id": 3,
"table":"oushu.public.table1",
"op": "delete",
"ts_ms": 1589362334564,
"record":{
"pkid":1
}
}
操作类型路径是描述 JSON 数据中,操作类型的 jsonPath,如样例中格式,则填写
/op操作类型格式是描述这段 CDC 数据的操作和对应的值,根据’op’字段中的值对应
INSERT:insert
UPDATE:update
DELETE:delete源表信息格式,是用来描述这条 CDC 数据来自哪张表,这里填写对应的 jsonPath,表名需要是全限定表名称,如样例中 CDC 数据中字段’table’已经是全限定表名,所以这里只需要填写
/table。如果需要db字段和schema字段来组合生成全限定表名,那么需要填写对应的取值路径
测试连接通过后进入到下一步选择处理对象
选择处理对象
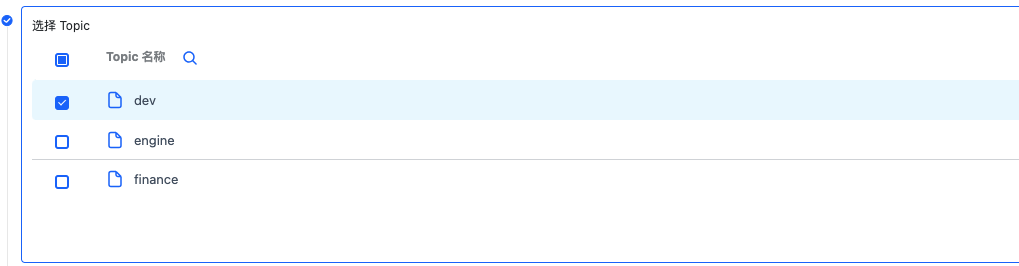
这里分为两个步骤选择 topic,表示从哪些 topic 中获取数据
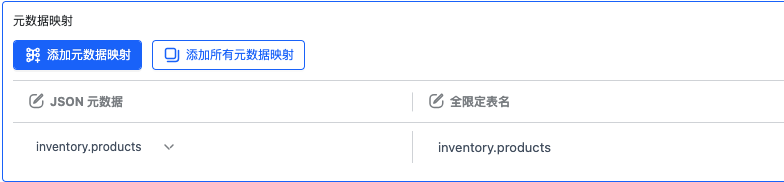
添加元数据映射(元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节),选中元数据后并填写对应的全限定表名,表示这个元数据和哪张源表关联上
选择数据目标 选择一个 OushuDB 数据目标。
配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 Kafka CDC 的方式抽取并导入到 OushuDB 的数据集成任务就创建完成了。