定量文件同步任务创建指南
本页目录
定量文件同步任务创建指南#
本章节介绍如何创建抽取定量文件,按照 CSV/JSON 格式解析后 upsert 到 OushuDB 的任务,下面用 HDFS->OushuDB 举例
前提#
已添加 HDFS 数据源,保证数据源的连通性,注意 HDFS 数据源中”工作目录”的指定,这将指定数据集成时可选的文件根目录。
已添加 OushuDB 数据源,保证数据源的连通性,访问用户有必要权限。
任务创建流程#
创建元数据
在数据源模块编辑已添加的 HDFS 数据源,添加元数据。元数据的创建和管理,详情请见数据源使用手册中的“元数据管理”章节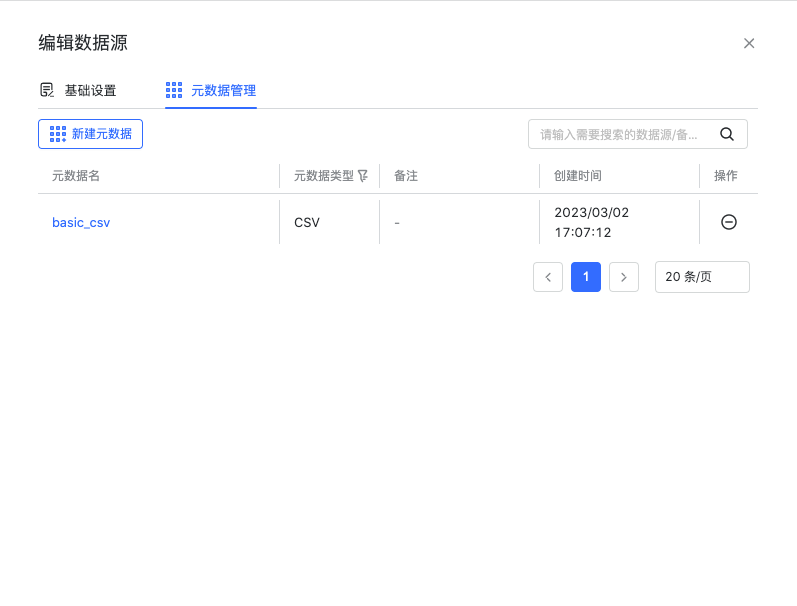
创建数据集成任务
选择数据源,接着选择模式,这里我们选择定量文件同步模式 测试连接通过后进入到下一步选择处理对象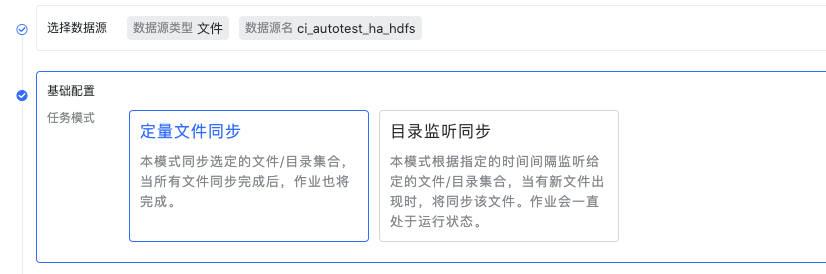
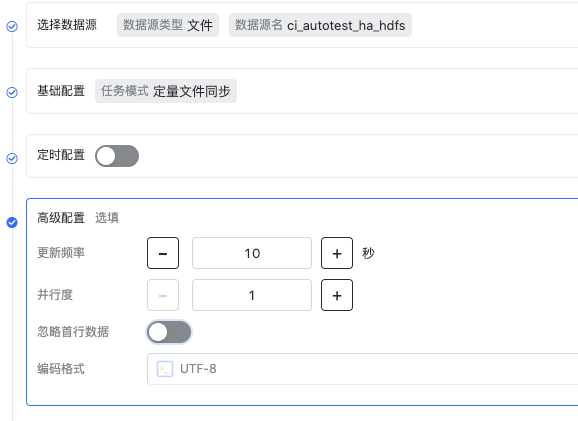
高级配置:
更新频率,影响写入目标的频率和记录 checkpoint 的频率,适当增加该值可以增加吞吐量。
并行度,即并发读取/写入。
忽略首行数据,勾选后读取每个文件时都会跳过首行。
编码格式,当前仅开放 UTF-8
选择处理对象
这里每个文件/目录对应一个元数据,勾选文件/目录后需要选择不同类型的元数据,这里支持 JSON 和 CSV 类型的元数据。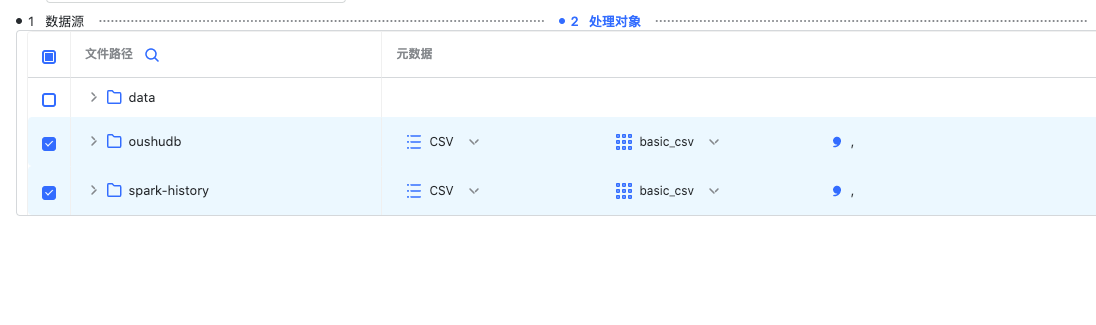 值得注意的是:对于 CSV 元数据,需要填写分隔符
值得注意的是:对于 CSV 元数据,需要填写分隔符选择数据目标
选择一个 OushuDB 数据目标。
配置列映射
在这里,您可以指定某个元数据对应的表要导入到某张目标表,是否是已有表/自动建表等,如果是自动建表需要手动配置主键。 点击“列映射”可以配置源表到目标表的列对应关系、名称、主键、类型等。 详情请见使用指南中的“创建任务-列映射”章节。
至此,一个从 HDFS 抽取,按照 CSV/JSON 格式解析后,upsert 导入到 OushuDB 的数据集成任务就创建完成了。