偶数AI小课堂:集成学习的Boosting技术(一)
大家好又到了偶数 AI 小课堂的时间了~

上节我们提到了机器学习中的集成学习以及Bagging思想,在随机森林的构建过程中,由于各棵树之间是相互独立的;在构建第m棵树的时候,不会考虑前面的m-1棵树。如果在构建第m棵子树的时候,考虑到前m-1棵子树的结果,会不会对最终结果产生有益的影响?
在这篇文章中,您将了解用于机器学习的Boosting方法。看完这篇文章,你会知道:
什么是boosting方法以及它通常是如何工作的; 学习如何使用AdaBoost算法;
假设提升是过滤观察的想法,留下弱学习器可以处理的那些观察,并专注于开发新的弱学习器来处理剩余的困难观察。
提升学习(Boosting)是一种机器学习技术,通过从训练数据构建模型,然后创建第二个模型来尝试纠正第一个模型中的错误来完成的。添加模型直到完美预测训练集或添加最大数量的模型。提升学习的每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式,就称为梯度提升(Gradient Boosting)。
Boosting指的是通过结合粗略和适度不准确的经验法则来产生非常准确的预测规则的一般问题。
提升学习技术的意义:如果一个问题存在弱预测模型,那么可以通过提升技术的方法得到一个强预测模型。 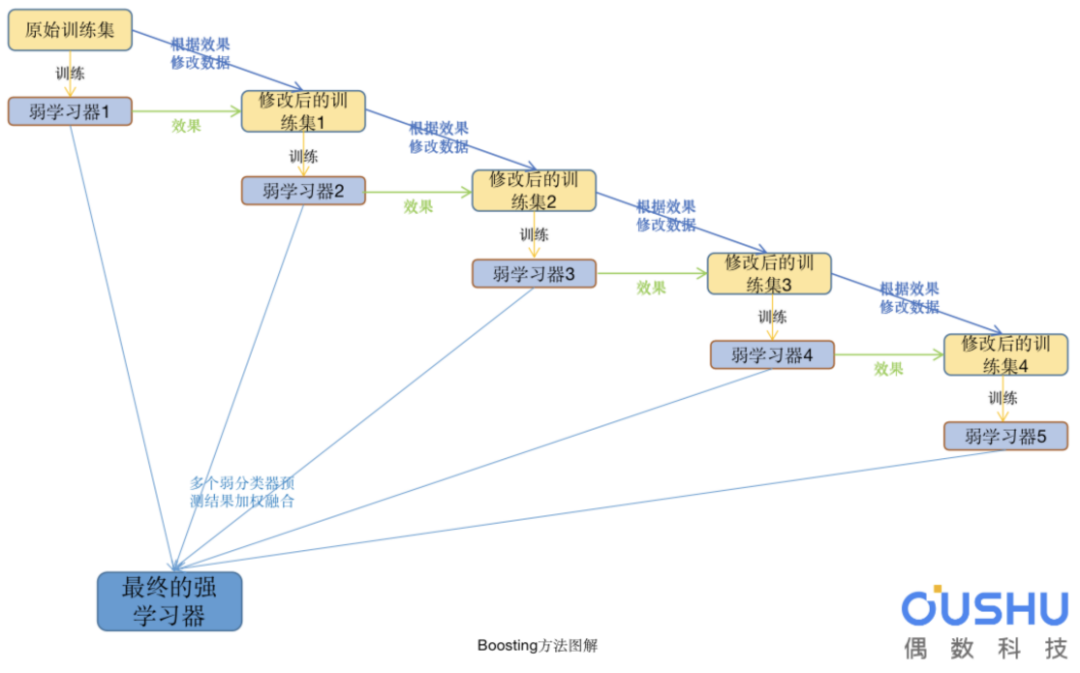
常见模型:
AdaBoost Gradient Boosting(GBDT) XGboost
图解Adaboost
Adaptive Boosting(AdaBoost)是第一个为二进制分类开发的真正成功的提升算法。这是理解boosting的最佳起点,现代提升方法建立在AdaBoost之上。
AdaBoost的核心就是求当前分类器的权重和更新样本的误差。它可以用于提高任何机器学习算法的性能。最好与弱学习器一起使用。
这意味着难以分类的样本会收到越来越大的权重,直到算法识别出正确分类这些样本的模型。
与AdaBoost一起使用的最合适也是最常见的算法是具有一层的决策树。因为这些树很短,并且只包含一个用于分类的决策,所以它们通常被称为决策树桩。
训练数据集中的每个实例都被加权。初始权重设置为:
Weight(Xi) = 1/N
其中Xi是第i个训练实例,N是训练实例的总数。(训练实例:即用于训练模型的样本数据)
Adaboost计算流程如下: 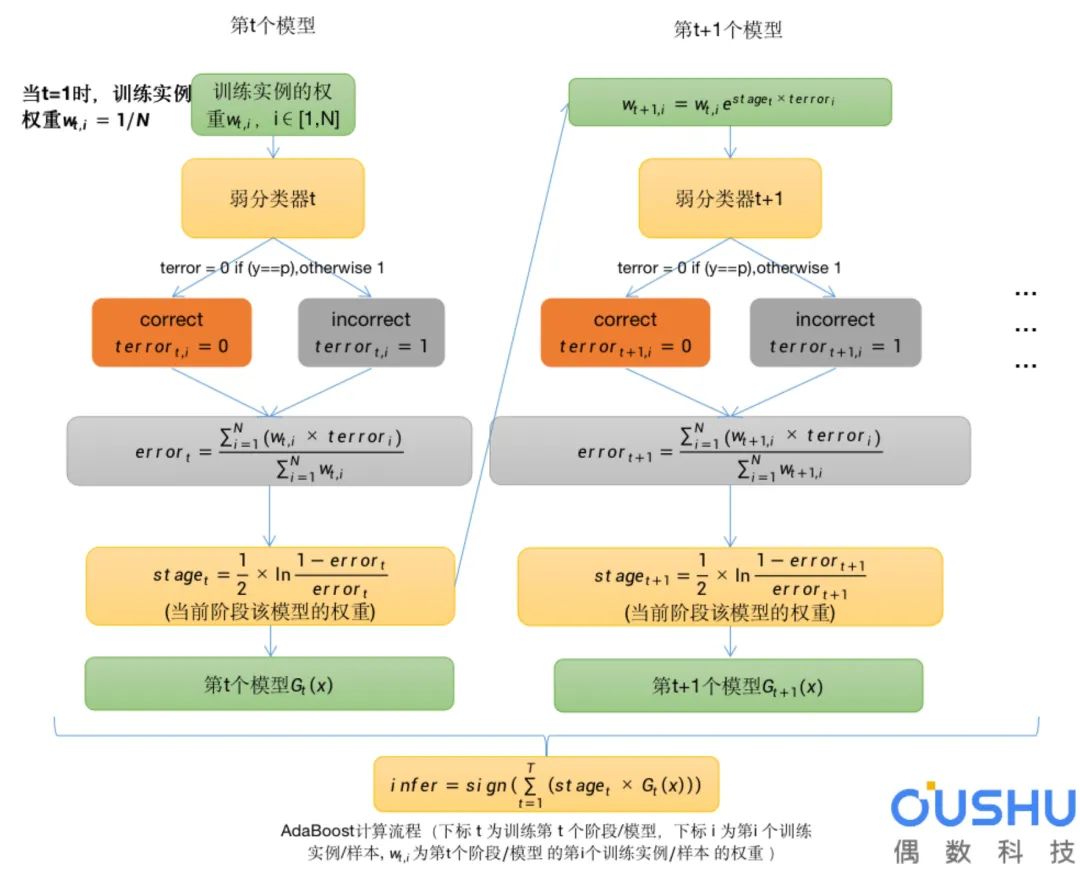
流程解析:
每个实例都有自己独立的权重w,通常我们会对w进行归一化,使得w之和sum(w)=1。
使用加权之后的样本作为训练数据,以弱分类器(决策树桩)进行训练。仅支持二元(两类)分类问题,因此每个决策树桩对一个输入变量做出一个决策,并为第一类或第二类输出+1或-1值。
为训练后的模型计算错误分类率。传统的计算方式如下:
其中error是误分类率,correct是模型正确预测的训练实例数,N是训练实例总数。例如,如果模型正确预测了100个训练实例中的68个,则错误率或误分类率为(100-68)/100或0.32 。
将以上方式修改为加权训练实例:
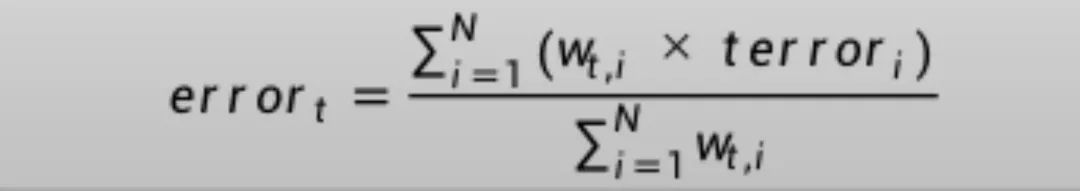
这是误分类率的加权和,w是训练实例i的权重,terror是训练实例i的预测误差,terror为1时是误分类,为0时是正确分类,sum是对N个实例的求和。
例如,如果我们有三个训练实例,权重分别为0.01、0.5和0.2.预测值为-1、-1和-1,实例中的真实输出变量为-1、1和-1,则terror为0、1和0。误分类率将计算为:
error = (0.01*0 + 0.5*1 + 0.2*0)/(0.01+0.05+0.2)
or
error = 0.704
为经过训练的模型计算阶段权值,该值为模型做出的任何预测提供权重。训练模型的阶段值计算如下:
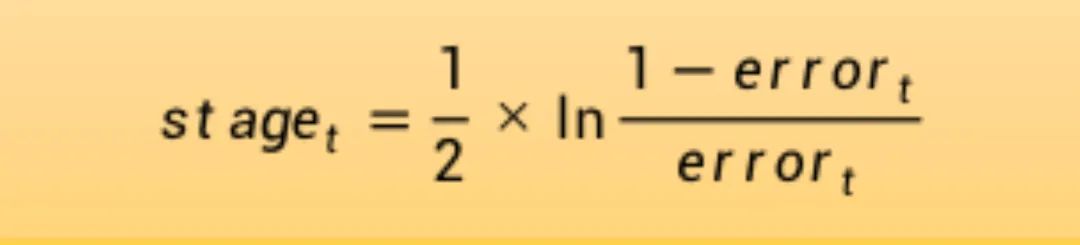
其中stage是用于对模型的预测进行加权的阶段值,即当前阶段模型的权重,ln()是自然对数,error是模型的误分类率。阶段权重stage的作用是,更准确的模型对最终预测的权重贡献更大。
更新训练权重,为错误预测的实例提供更多的权重,为正确预测的实例提供更少权重。例如,用以下方法更新一个训练实例的权重(w):
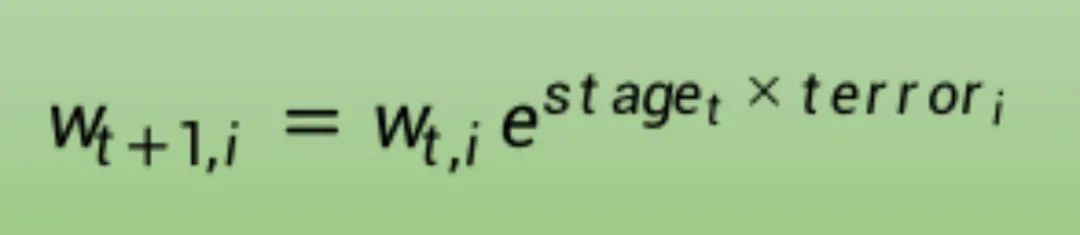
其中w是特定训练实例的权重,e是数值常数,stage是弱分类器的误分类率,terror是弱分类器预测输出变量的错误训练实例,评估为:
terror = 0 if (y==p), otherwise 1
其中y是训练实例的输出变量,p是弱学习器的预测结果。
如果训练实例被正确分类,则权重不发生改变,如果被错误分类,则增大权重。
Adaboost 集成:
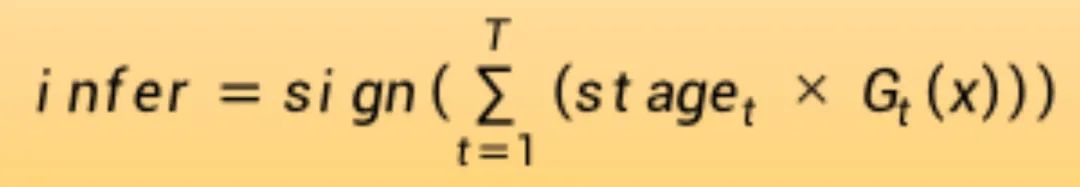
将之前训练的弱模型按顺序添加,使用加权的训练数据进行训练。
该过程一直持续到创建了预设数量的弱学习器(用户参数)或无法对训练数据集进行进一步改进。
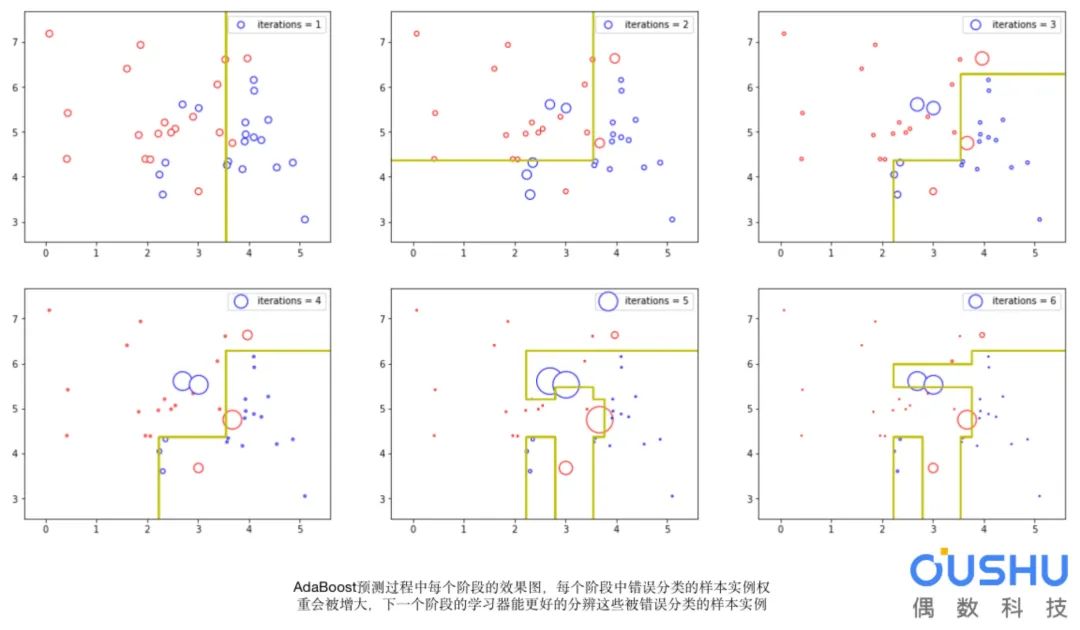
完成后,将得到一组弱学习器,每个学习器都有一个阶段值。如下图,我们使用图中○的大小代表点的权重:
使用AdaBoost进行预测:
通过计算弱分类器的加权平均值来进行预测。
对于新的输入实例,每个弱学习器G(x)将预测值计算为+1.0或-1.0。预测值由每个弱学习器阶段值stage加权。集成模型的预测被视为加权预测的总和。如果总和为正,则预测为第一类,如果为负,则预测为第二类。
例如,5个弱分类器可以预测值1.0、1.0、-1.0、1.0、-1.0。从多数投票来看,该模型将预测为值1.0或第一类。这5个弱分类器的阶段加权值可能分别为0.2、0.5、0.8、0.2和0.9。计算这些预测的加权会得到-0.8的输出,这将是-1.0或第二类的集合预测。
AdaBoost的数据准备
本节列出了一些启发式方法来为AdaBoost准备数据。
数据质量:由于集成方法继续尝试纠正训练数据中的错误分类,因此需要注意训练数据的质量。
离群值:离群值将迫使整体陷入困境,努力纠正不切实际的情况。我们可以从训练数据集中删除这种情况。
噪声数据:噪声数据,特别是输入变量中的噪声可能会对模型产生负面影响。可以尝试从训练数据集中隔离和清理这些噪声数据。

