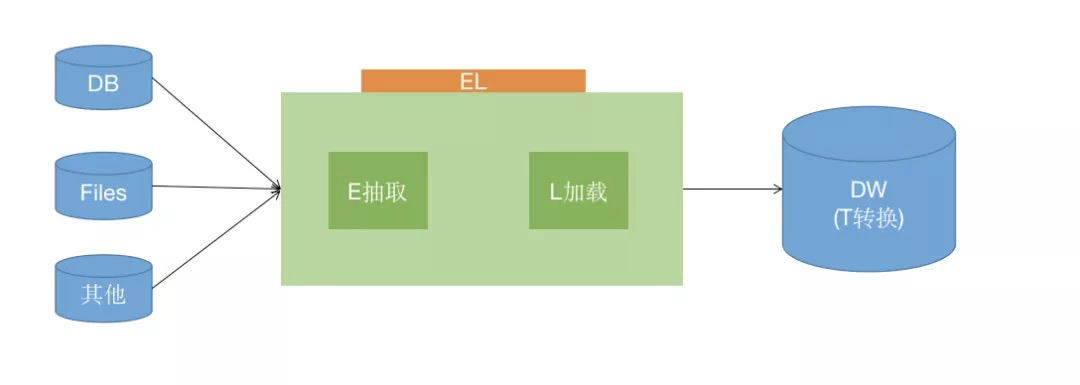
什么是数据同步工具(ETL、ELT)
数据同步工具ETL或者ELT的作用是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。数据同步是大数据项目重要的一个环节。通常情况下,在大数据项目中数据同步会花掉整个项目至少1/3的时间,数据同步工具设计的好坏直接关接到BI项目的成败。
关于ETL与ELT的区别
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
ETL其实并不是一个新的概念,大家经常使用的像Informatica、Kettle、DataStage等,就是传统的ETL数据同步工具。ETL的理念着重体现在一些数据清洗转化功能,比如空值处理、规范化数据、数据替换、数据验证等等。在数据湖或数据中台则往往会采用ELT的方式进行数据同步。ELT是一个比较新潮的概念,相比于ETL,从功能上来说没有差异,只是换了一个顺序。差别在于,如果采用ELT的方案,首先把数据用一种高效的方式从数据源抽取出来,然后在数据仓库中进行数据的转换处理。这种ELT的方式相比于ETL有很大的优势,而本文介绍的偶数数据中台Lava中的数据同步工具,使用的就是ELT这种理念。
作为一个数据同步工具,偶数的数据同步工具支持很多常用数据源比如DB2、Oracle、MySQL、SQLServer、Postgresql等关系型数据库以及HDFS等。偶数的数据同步工具符合ELT的理念,把数据的转换处理交给目标数据仓库来做。并且很好的利用目标数据仓库,例如OushuDB的高效特性来进行数据同步,块级别的并发导入效率远远高于JDBC的方式导入。基于OushuDB的高效性能,ELT的优势更加明显:传统的ETL需要将数据加载到临时空间中,而且随着数据大小的增加,转换时间也会增加。但是在ELT过程中,速度不会数据大小的影响,而且仅需加载到目标系统一次,无需使用临时空间。在ELT的理念下,数据转换依赖强大的目标系统,相比ETL在数据抽取过程中对数据处理的复杂性,ELT的方式更加高效。通过对目标数据仓库的调优,ELT可获得数倍的效率提升。采用ELT模式,我们可以避免构建一个专有的数据转换集群,而是通过一个通用的、易于创建和维护的分布式计算集群来完成所有的工作。分布式的数据加载、强大的任务监控、简单的操作步骤以及傻瓜式的部署方式,使得偶数数据中台Lava中的数据同步工具可以为构建数据仓库或者搭建数据中台提供强大助力。
关于偶数
偶数科技是一家总部位于北京的云数据仓和AI产品提供商,致力为全球各行业客户提供大数据和AI产品及行业解决方案。我们的愿景和使命是“用科技让人类只为兴趣而工作”。目前偶数科技已经获得来自红杉中国、红点中国、金山云以及产业科技巨头的融资。
公司核心产品“偶数数据云Oushu Data Cloud”由“新一代云原生数据仓库OushuDB”、“自动化机器学习平台LittleBoy”以及“数据管理平台Lava ”组成。产品已在金融、互联网、电信、政府等行业数百家头部企业得到广泛应用。
偶数科技同时是微软加速器和腾讯加速器成员企业,并入选美国著名商业杂志《快公司》 “中国最佳创新公司 50”榜单。