国外企业指标管理实践:Airbnb(下)
上篇文章,我们介绍了Airbnb打造Minerva指标平台的初衷,以及Minerva的设计原则。这篇文章,我们继续来详细拆解下Minerva的自恢复(Self-healing)、一致性(Consistent)、高可用(Highly available)、可验证(Well tested),以及Airbnb内部用户是如何使用Minerva高效完成疫情影响分析的。
错过上一篇的同学可以通过传送门了解:
自恢复(Self-healing)
Minerva通过智能警报发现数据链路的异常,并实现自动化回填,这样可以更好的应对突发状况,这些状况可能包括:①数据加工链路出现bug,②集群基础设施不稳定,③调度程序中断,④上游数据超时等等。
实现自动化回填,首先要能感知到数据缺失与否。每次作业开始时,Minerva都会检查现有数据是否有缺失。如果发现有缺失的数据,它会自动将其包含在当前运行中。也就是说单一运行可以动态决定计算窗口并回填数据。任务失败时,用户不需要手动重置任务。
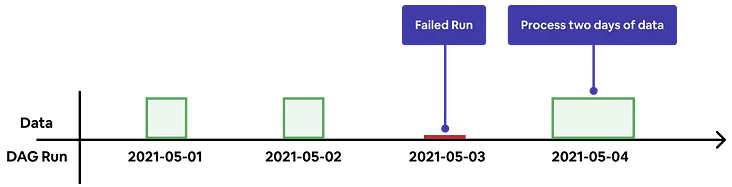
失败运行中缺失的数据被识别并作为未来运行的一部分进行计算
如果Minerva识别到相关数据版本不存在数据,它就会自动从其上游数据集中生成数据。如果回填窗口非常过长(例如几年),Minerva可能会生成一个跨度较长时间的查询,如此高的负载会造成资源使用的高峰。虽然Airbnb的基础计算引擎是可扩展的,但是一旦基础设施有点风吹草动,长时间运行的查询就很容易受到影响,如果查询失败,则恢复成本很大。
另一个极端,使用像一天这样的小窗口回填太慢。为了提高可扩展性、减少运行时间和提高恢复能力,Airbnb实施了批量回填。
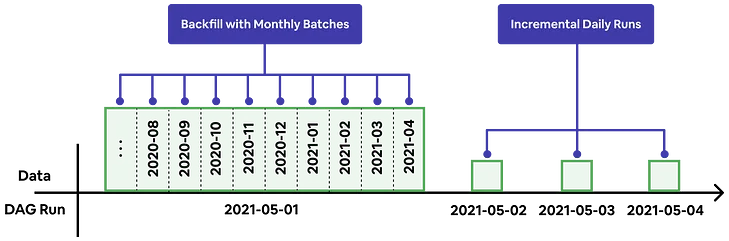
在 2021-05-01 任务中,单个作业被分解为多个并行的每月批次
通过批量回填,根据特定数据集的可扩展性,Minerva将工作分成几个日期范围。例如,Minerva可以将两年数据的回填分成24个一个月的批次运行。失败的批次将在下一次运行中自动重试。
这种自动化的数据集管理让不同团队重新理清职责。基础设施问题由平台团队负责,而数据问题则由相应的产品或数据科学团队负责。不同的数据集需要不同级别的升级处理。Minerva会根据错误类型智能地提醒对应团队,并通知下游应用数据延迟。这样,在Airbnb内部运营中,责任和能力就更好的匹配,避免了以前动不动就召集多个团队会诊来解决问题。
一致性(Consistent)
Minerva 的指标库会经常被用户修改,如何确保由Minerva生产的数据集始终是一致和最新的?答案在数据版本控制,也就是配置文件中指定所有重要字段的哈希值。当更改影响生成数据的字段时,数据版本就会自动更新。每个数据集都有一个独特的数据版本,因此当版本更新时,就会自动创建一个新的数据集并进行自动回填。
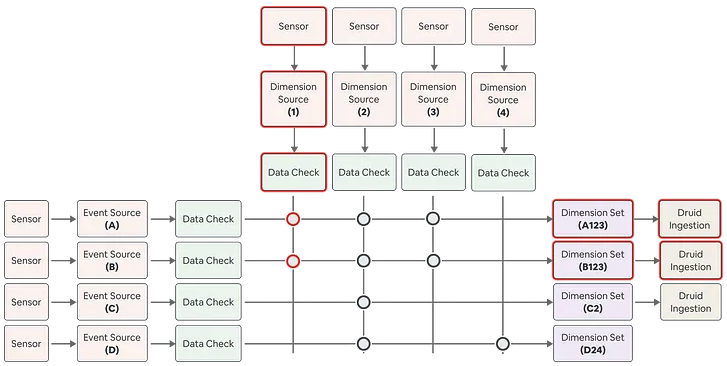
单个维度的更新可以触发所有使用该维度的数据集的回填
上图中我们可以看到,维度源 1 中的某个维度已更新。鉴于这个维度被两个维度集(即 A123 和 B123)使用,与这两个维度集相关联的数据版本也会相应更新。随着数据版本的更新,这两个维度集的将启动自动回填。在Minerva中,变更产生新的数据版本,进而触发回填,Minerva维持跨数据集数据一致性的方法,确保上游变更有效、可控的传播到所有下游数据集。
高可用(Highly available)
了解了Minerva 通过数据版本来维护数据一致性,那就会产生一个问题,用户变更的速度可能快于回填的速度,也就会出现一个快速变化的数据集可能会永远处于回填模式,导致显著的数据停机时间。
为了解决这个问题,Airbnb创建了一个名为 Staging 的并行计算环境。Staging 其实是生产环境的副本,根据待处理的用户配置构建。在替换生产环境之前,通过共享环境中自动执行回填,Minerva 将多个未发布的变更应用于一组回填。这样一来①用户不再需要跨团队协调变更和回填;②数据分析应用不再经历数据停机时间。
Staging 环境的数据流如下:
①用户在本地环境中创建并测试新变更。
②用户将变更合并到 Staging 环境。
③Staging 加载配置,可以通过必要的生产配置进行补充,回填修改过的数据集。
④回填完成后,Staging 配置被合并到生产环境。
⑤生产环境立即采用新定义,向数据分析应用提供数据服务。
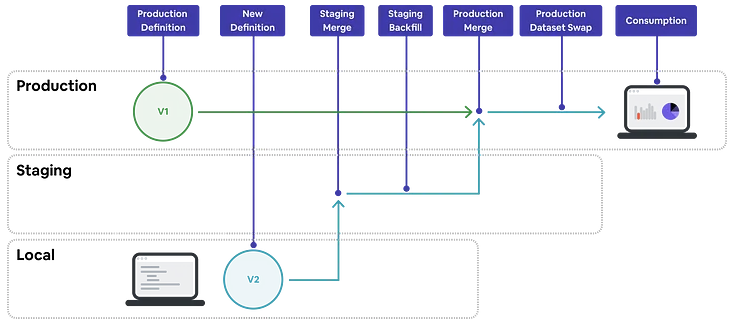
配置更改首先加载到 Staging,在准备发布前合并到 Production
暂存环境暂存环境使我们能够在用户频繁更新定义的情况下,同时保持关键业务指标的一致性和可用性。这对于公司内部许多大规模数据迁移项目的成功至关重要,并且它帮助我们专注于数据质量,从而改进了我们的数据仓库。
即使用户频繁更新定义,Staging 也能让Airbnb的关键业务指标保持一致性和可用性。这使得Airbnb内部大规模数据迁移项目更加得心应手,可以在专注于数据质量的同时改进数据平台。
可验证(Well tested)
定义指标和维度是一个不断迭代的过程。有时候用户经常发现原始数据会有一些波动,需要深入了解他们的源数据是如何产生的,因此Minerva 就必须帮助用户验证数据的正确性,了解源数据发生了什么,这样才能快速迭代。
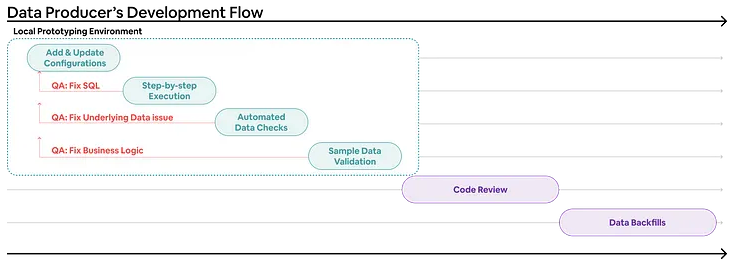
用户使用 Minerva 原型工具的开发流程
为了实现可验证这一点,Airbnb创建了一个引导式的原型工具,它从生产环境读取数据,写入到一个隔离的沙盒。利用 Minerva 任务流执行逻辑,在用户本地修改之上快速生成样本数据。这样用户能够利用新数据和已有数据检查质量,同时也可以提供样本数据来验证输出是否符合预期。
有了这样的验证工具,就能清晰地展示了 Minerva 任务流是如何一步步计算出结果的,计算逻辑可见既可以让用户独立调试,同时也是Minerva 开发团队所依赖的测试环境。
在性能方面,根据用户配置的日期范围和抽样数据,该原型工具可以约束测试数据的大小,极大加快了执行时间,从几天时间缩短到几分钟。
用Minerva分析疫情对旅行的影响
旅游民宿平台受大环境影响明显,尤其是在疫情期间,市场发生巨变,疫情完全改变了人们在 Airbnb 上的旅行方式。接下来我们以Airbnb的一个典型用户翠花的视角,看下用户是如何通过Minerva将数据迅速转化为分析和决策的。
翠花从历史数据了解到,Airbnb对城市与非城市目的地的需求大约是两倍。在疫情期间,翠花假设旅行者会避开大城市,选择人群不太密集的目的地。
为了证实这个假设,翠花决定做一个分析,按 dim_listing_urban_category 维度划分夜间预订数(nights_booked)指标。由于夜间预订数是公司的主要指标之一,翠花很容易在 Minerva 中找到其定义。然而,她关心的房源列表维度在 Minerva 中并不可用,于是翠花利用美国宇航局(NASA)发布的全球城乡映射和世界人口密度(GPW v4)来设计一个新的 Minerva 维度。

翠花在维度源中配置新维度
翠花还将这个新维度的定义添加到Airbnb内部用于追踪疫情对业务运营影响的维度集中。

翠花将新维度添加到 Central Insights 团队拥有的疫情SLA 维度集中
为了在 Minerva 中验证这个新维度,翠花使用了上文提到的原型工具来计算包含这个新维度在内的数据样本。几分钟内就可以确认配置有效,数据正确组合。
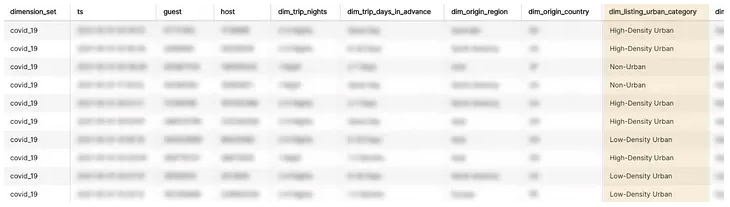
翠花能够在几分钟内与同事分享样本数据
在验证了数据之后,翠花向 Core Host 团队提交了一个代码审查的拉取请求,该团队负责所有房源元数据的定义。这个拉取请求包括了执行日志、计算成本估算,以及便于审查的样本数据链接。在获得批准后,翠花将更改合并到了共享的 Staging 环境中,经过几个小时,修改过的数据集的全部历史自动进行了回填,并最终合并到了生产环境。

内部用户可以清楚地看到,随着旅游业的反弹,客户需求发生变化
利用新创建的数据集,公司内各团队和领导开始在他们的仪表板中突出显示并跟踪用户行为变化。这一关键绩效指标的变化还促使了Airbnb重新设计关键产品页面,以适应用户变化的出行习惯。

跨事件源(y 轴)采用新的维度源(红色)
在这个用户实例中,翠花先是定义一个新的维度,然后将其添加到已有的指标标准中,获得批准后,在几天内为多个团队更新大量关键数据集,而这些仅是通过几十行 YAML 配置完成的。
到目前为止,Minerva 中已有超过 12,000 个指标和 4,000 个维度,有超过 200 个数据生产者,横跨不同的职能部门(例如数据、产品管理、财务、工程)和团队(例如核心产品、信任、支付)。现在大多数团队都将 Minerva 视为 Airbnb 的首选分析、报告和实验框架。
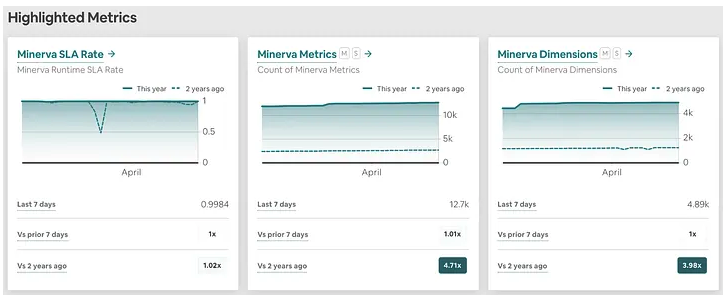
过去两年Airbnb 对 Minerva 的使用率大幅增长
了解更多的指标相关内容,可以关注我们,或者添加下方群管理员微信领取Kepler介绍PPT。

