关于实时数据的疑问和期待,这篇一次讲透!
做过数据分析,尤其是做过高频率、快节奏的运营分析同学,想必对于实时交互式查询一定不陌生。
什么是实时交互式查询?
交互式查询是一种在用户与数据库之间进行即时交互的查询方式。这意味着用户可以向数据库提出查询请求,并在几秒钟或更短的时间内获得结果。交互式查询通常用于对数据进行快速探索、实时分析和决策。
交互式查询距离全面的实时数据平台有哪些差距?
大多数厂商和用户会认为能实现交互式查询,实时数据处理就算成了,至于实时离线整合查询、数据一致性等问题,可能干脆就没有考虑过,或者由于默认技术不可行而不再关注了。
实时离线整合查询是什么?
目前交互式查询大多是查询当天几秒钟或者几分钟新增的实时数据,但想要将实时数据和历史离线数据结合起来进行查询分析,就会很难实现。
举个例子,在2025年三八妇女节当天,某个直播平台需要临时做一个定向的优惠券发放活动,需要在3月8日18:00筛选出:截止5分钟前,过去3年内,在直播间累积消费金额2万元以上的女性用户。

作为运营分析同学,你很难将当天的实时下单记录、历史下单记录和用户基本信息整合起来进行分析,因为他们根本就不在一个系统。
为什么实时、离线数据不在一个系统?
处理实时数据和离线数据进行数据分析时,数据源通常来自多个业务系统(如OLTP数据库、传感器、日志文件),存储在合适的数据存储介质中,以便后续处理和分析。
实时数据:
像传感器、日志文件等实时数据流,通常使用流处理技术(Kafka、Flink等)来实时处理,然后会被存储在列式数据库(如ClickHouse)、NoSQL 数据库(如Cassandra)或者内存数据库(如Redis)。
离线数据:
离线数据通常是批量导入的历史数据或者定期更新的数据快照。通常被存储在大数据存储系统中,如Hive,分布式文件系统(如HDFS)、对象存储(如S3)。

在同时处理实时数据和离线数据时,自然会出现数据不一致的问题。
为什么会产生数据不一致?
①处理逻辑差异:
实时数据和离线数据使用不同的数据抽取频度从源系统导出,比如实时数据是实时流式抽取出来的,而离线数据是每天通过ETL工具离线导出,然后根据不同逻辑进行处理和转换。例如,实时数据需要经过流式处理引擎进行实时计算,而离线数据则经过批处理作业进行离线分析。如果这些处理逻辑存在差异,就可能会导致数据处理结果的不一致。
②数据格式和结构不兼容:
实时数据和离线数据通常具有不同的数据格式和结构,例如字段名称、数据类型、数据粒度等方面都会存在差异。如果在数据处理过程中未进行正确的数据转换和映射,就会导致数据格式和结构的不一致。
如何解决数据不一致,并实现实时离线整合?
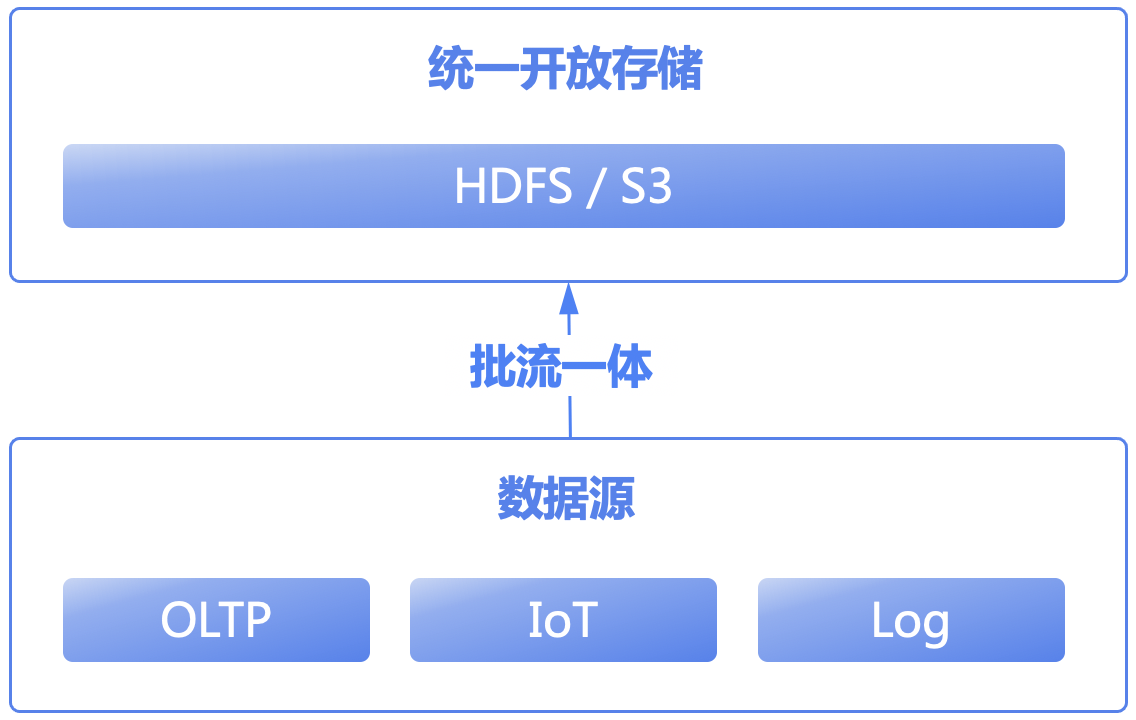
解决的方法可以从几个方面入手:①统一开放的存储、②批流一体数据处理、③事件溯源、④统一元数据管理。
①统一开放存储:建立一套统一的、开放的存储,将实时数据和离线数据都存储在其中,如分布式文件系统上(HDFS)或对象存储(S3),让实时数据和离线数据共享同一份存储,简化数据管理和维护。
②批流一体数据处理:可以利用市场上成熟的批流一体同步工具,将实时数据流和离线数据批处理融合在一起。这样可以统一数据处理逻辑,大幅降低不一致性的可能性。
③事件溯源(Event Sourcing):对实时数据和离线数据进行事件溯源,将数据的变更记录为事件,然后通过事件日志进行数据同步。这样可以确保所有数据的变更都能被追溯和记录,从而保持数据一致性。
④版本控制和元数据管理:对数据进行版本控制和元数据管理,记录数据的变更历史和元数据信息。这样可以跟踪数据的变更和来源,及时发现和解决数据不一致的问题。
批流一体工具需要具备什么样的能力?
①批流作业集成:首先需要能够同时支持实时数据流和批处理作业的集成,即能够在同一个工具中管理和调度实时流处理任务和批处理作业。
②数据一致性保障::能够保障数据的一致性,即在数据同步过程中能够确保数据的完整性和准确性,避免数据丢失或重复。
③灵活的数据转换和处理::包括数据清洗、格式转换、字段映射等,以满足不同数据源和目标系统之间的数据兼容性和一致性需求。
这里为偶数的数据工厂Wasp打一个广告,它很好的满足了批流作业集成、数据一致性保障、灵活的数据转换和处理。
使用统一开放的存储,那很多计算引擎就用不了?
现有的很多数据平台确实是使用了多种计算引擎,比如离线链路用 Hive/Spark,实时处理再加上 Flink;如果需要实时查询,要再加上 ClickHouse/Drill/Presto;如果需要做数据的离线归档,还需要 Hive;为了满足一些高并发点查询需求,还要再引入了HBase 和 MySQL。
疯狂引入这么多组件,人为制造了多个数据孤岛,其长期弊端我们暂且不表,仅是运维整个架构就非常困难,而且学习和开发成本非常高。
如今,我们已经推演出未来最佳的实时数据架构——统一开放存储+批流一体,那么就需要在计算层面满足开放存储,性能和并发兼顾的产品。OushuDB作为实时湖仓领域的核心产品,经过多年沉淀,完全实现Hive、Presto、ClickHouse、HBase等引擎的功能,引入OushuDB取代原有复杂组件,能轻松实现统一开放存储+批流一体的实时数据架构,还可以极大简化系统开发和运维的复杂度。
追求毫秒级时效,HDFS的并发写入有限,有没有什么好办法?
有时候一些业务场景追求秒级或者毫秒级时效,HDFS的并发写入确实是有上限的,当实时数据量过大,HDFS方案可能不能满足业务需求。
在使用OushuDB作为实时数据平台核心计算引擎的前提下,可以采用更极致的实时方案。在HDFS基础上,引入一个支持实时数据读写更新的分布式存储,且该存储和HDFS都可以作为OushuDB的内表,这就是偶数分布式表存储Magma。Magma负责实时数据区,而原来的离线存储既可以使用HDFS也可以使用Magma。
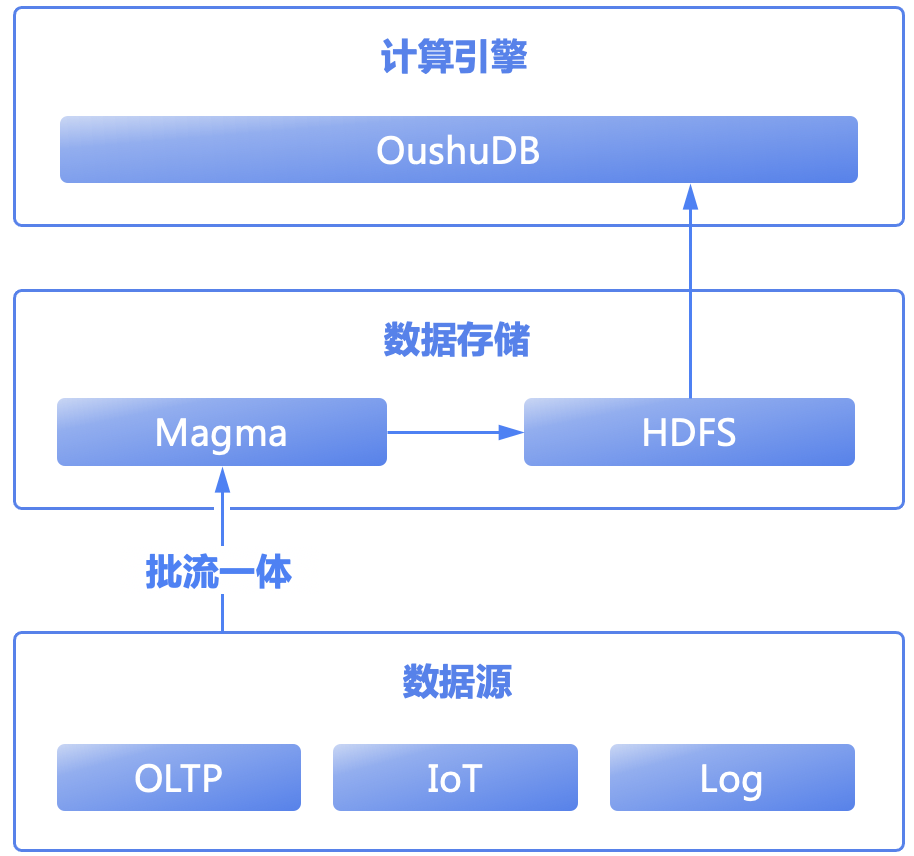
以上就构成了Omega全实时架构的初步雏形了。Omega架构其实已经不是一个神秘的架构,早在2021年初就被提出。

