由于云技术的推动,企业对于跨公司、跨行业、跨领域的综合型数据的需求日趋明显,不同类型、格式数据之间的关联性碰撞越来越激烈,刺激着数据技术的创新发展,逐渐形成了大数据生态结构。当前面临的问题的复杂性、综合性、交叉性,导致数据的使用成本越来越高,企业迫切需求能够有效打破数据孤岛、解决数据主权、统一数据汇聚和共享的混合式数据平台,数据湖应运而生。
什么是数据湖
早在2011年,福布斯的一篇文章中介绍了数据湖(Data Lake)的概念,针对数据仓库中的开发周期长、维护、开发成本高、丢失细节数据等不足进行的补充。数据湖是一种大型数据存储库和处理引擎。它能够大量存储各种类型的数据,拥有强大的信息处理能力和处理几乎无限的并发任务或工作的能力。维基百科对数据湖的解释是:数据湖是一种在系统或存储库中以自然格式存储数据的方法,它有助于以各种模式和结构形式配置数据,通常是对象块或文件。形象的描述数据湖是指用湖来形容存储数据的平台,流入湖中的水表示未经处理的原始数据,这些数据包括表格、文本、声音、图像等等。湖中的水就代表存储的各种数据,在湖中可以进行数据的处理、分析、建模、加工,处理后的数据仍然可以留在湖中。而流出的水代表经过分析后,下游所需要的数据,再到达用户端,提供信息得出结论。数据湖的主要思想将是不同类型、不同领域的原始数据进行统一的存储,包括结构化数据、半结构化数据和二进制数据,形成一个容纳所有形式的数据集中式数据存储集。这个数据存储集具备庞大的数据存储规模,PB级别的计算能力,满足多元化的数据信息交叉分析以及大容量、高速度的数据管道。数据湖的优势
轻松地收集数据:数据湖与数据仓库的一大区别就是,Schema On Read,即在使用数据时才需要Schema信息;而数据仓库是Schema On Write,即在存储数据时就需要设计好Schema。这样,由于对数据写入没有限制,数据湖可以更容易的收集数据。从数据中发掘更多价值:数据仓库和数据集市由于只使用数据中的部分属性,所以只能回答一些事先定义好的问题;而数据湖存储所有最原始、最细节的数据,所以可以回答更多的问题。并且数据湖允许组织中的各种角色通过自助分析工具,对数据进行分析,以及利用AI、机器学习的技术,从数据中发掘更多的价值。消除数据孤岛:数据湖中汇集了来自各个系统中的数据,这就消除了数据孤岛问题。具有更好的扩展性和敏捷性:数据湖可以利用分布式文件系统来存储数据,因此具有很高的扩展能力。开源技术的使用还降低了存储成本。数据湖的结构没那么严格,因此天生具有更高的灵活性,从而提高了敏捷性。数据湖与数据仓库的区别
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。数据湖概念2011年被提出来,最初数据湖是数据仓库的补充,是为了解决数据仓库漫长的开发周期,高昂的开发、维护成本,细节数据丢失等问题出现的。数据湖与数据仓库很类似,都是数据存储,两者之间主要区别如下图所示: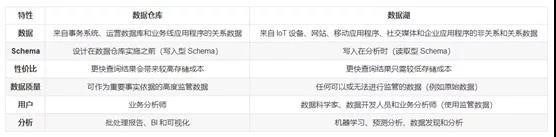
数据仓库是优化后的数据库,在存储数据之前要先定义好数据结构。而数据湖是一个数据存储的平台,不需要定义数据,能够自由存储不同类型的数据。在加载数据时,数据仓库需要预先定义,即写时模式;数据湖则是在准备使用数据的时候定义数据,即读时模式。因此,数据湖提高了数据模型的定义灵活性,更能满足不同业务的需求。湖仓一体
随着数据湖的优势被越来越多的企业看到,越来越多的企业开始融合数据湖和数据仓库的平台,不仅可以实现数据仓库的功能,还实现了各种不同类型数据的处理功能、数据科学、用于发现新模型的高级功能,这就是所谓的湖仓一体。
可管理性:湖仓一体提供完善的数据管理能力。数据湖中会存在两类数据:原始数据和处理后的数据。数据湖中的数据会不断的积累、演化,因此包含以下数据管理能力:数据源、数据连接、数据格式、数据schema(库/表/列/行)。同时,数据湖是单个企业中统一的数据存放场所,因此,还具有一定的权限管理能力。可追溯性:提供一个企业中全量数据的存储场所,需要对数据的全生命周期进行管理,包括数据的定义、接入、存储、处理、分析、应用的全过程。一个强大的数据湖实现,需要能做到对其间的任意一条数据的接入、存储、处理、消费过程是可追溯的,能够清楚的重现数据完整的产生过程和流动过程。丰富的计算引擎:提供从批处理、流式计算、交互式分析到机器学习等各类计算引擎。一般情况下,数据的加载、转换、处理会使用批处理计算引擎;需要实时计算的部分,会使用流式计算引擎;对于一些探索式的分析场景,可能又需要引入交互式分析引擎。随着大数据技术与人工智能技术的结合越来越紧密,各类机器学习/深度学习算法也被不断引入,可以支持从HDFS/S3上读取样本数据进行训练。因此,湖仓一体解决方案提供计算引擎的可扩展/可插拔。多模态的存储引擎:湖仓一体本身内置多模态的存储引擎,以满足不同的应用对于数据访问需求(综合考虑响应时间/并发/访问频次/成本等因素)。但是,在实际的使用过程中,为了达到可接受的性价比,湖仓一体解决方案提供可插拔式存储框架,支持的类型有HDFS/S3等, 并且在必要时还可以与外置存储引擎协同工作,满足多样化的应用需求。偶数科技的数据云平台(Oushu Data Cloud)是新一代的数据基础设施,可以轻松实现湖仓一体解决方案,它能够依托云原生特性、计算存储分离架构、强ACID特性、强SQL标准支持、高性能并行执行能力等一系列底层技术的变革,实现高弹性、强扩展性、强共享性、强兼容性、强复杂查询能力、自动化机器学习支持等上层技术能力的变革,最终帮助企业有效应对大规模、强敏态、高时效、智能化等愈发明显的数字化趋势。
关于偶数
偶数科技是一家总部位于北京的云数据仓和AI产品提供商,致力为全球各行业客户提供大数据和AI产品及行业解决方案。我们的愿景和使命是“用科技让人类只为兴趣而工作”。目前偶数科技已经获得来自红杉中国、红点中国、金山云以及产业科技巨头的融资。
公司核心产品“偶数数据云Oushu Data Cloud”由“新一代云原生数据仓库OushuDB”、“自动化机器学习平台LittleBoy”以及“数据管理平台Lava ”组成。产品已在金融、互联网、电信、政府等行业数百家头部企业得到广泛应用。
偶数科技同时是微软加速器和腾讯加速器成员企业,并入选美国著名商业杂志《快公司》 “中国最佳创新公司 50”榜单。

