不容错过:2024 VLDB Keynote演讲—— Samuel Madden
8月26日-30日,全球数据库领域顶级学术会议VLDB 2024在广州隆重举行,这是VLDB自2014年在杭州举行后,时隔10年重回中国。

在所有学术会议中都备受关注的Keynote演讲,本次也毫无意外的座无虚席。小编有幸在现场记录,今天就跟大家分享下Keynote演讲嘉宾Samuel Madden的研究内容。
《为世界上所有字节搭建数据库,我又是如何学会查询并爱上人工智能的》
我们生活在一个非常激动人心的时代,AI模型的生成能力令人难以置信,是我们这代人正在经历一次的技术变革。我认为AI将改变我们构建数据系统的方式,我们拥抱AI热潮,但是也要结合数据库任务来理解数据库社区在这一变革中的角色。

AI模型解锁了对任何类型数据提问的能力,打破了传统数据库表格的限制。我们不难发现AI系统需要处理大量文档和信息,提取知识并合成结构化表示,数据管理系统的一个长期目标就是构建能够在成本效益高的方式下计算大量非结构化数据集合的定量洞察的系统,这是数据库和数据系统社区应该关注的。

当下,从公司内部的文件中提取事实、从科学论文中提取数据,或从图像和视频集合中提取指标都既困难又昂贵。想要回答一个实质性的AI驱动查询的程序员必须协调大量的模型、提示和数据操作。即使对于一个单一的查询,程序员也必须做出大量判断,例如选择模型、正确的推理方法、最具成本效益的推理硬件、理想的提示设计等。随着查询的变化和技术环境的快速发展,最优决策组合也会发生变化。
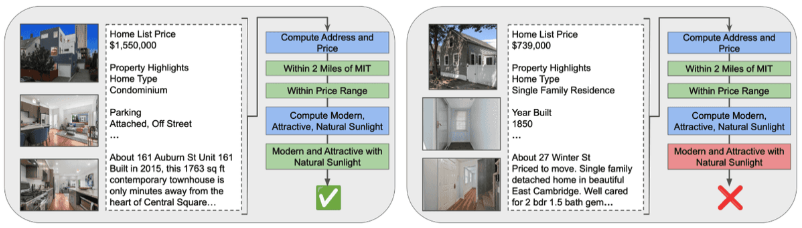
现代数据库系统使用的是一种高级的编程方式,叫做“声明式”编程。这种方式让程序员只需要告诉数据库他们想要什么样的数据,而不需要告诉数据库怎么去找到这些数据。这种编程方式给数据库很大的自由度,数据库可以自己决定怎么存储数据,以及怎么执行查询操作。这种方式对传统的数据库很有效,它也非常适合新的AI应用,尤其是那些使用大型语言模型的AI应用。这些AI应用可以帮助我们查询各种类型的文档,比如图片、PDF文件、文本文件、视频等。

今天我将为大家介绍我们研究的PALIMPZEST系统。PALIMPZEST可以简单地用声明式语言定义并处理AI驱动的分析查询,它使用其成本优化框架来实现查询计划,以在运行时间、成本和输出数据质量之间获得最佳平衡。

我们描述了AI驱动分析任务的工作负载、PALIMPZEST使用的优化方法以及原型系统本身。
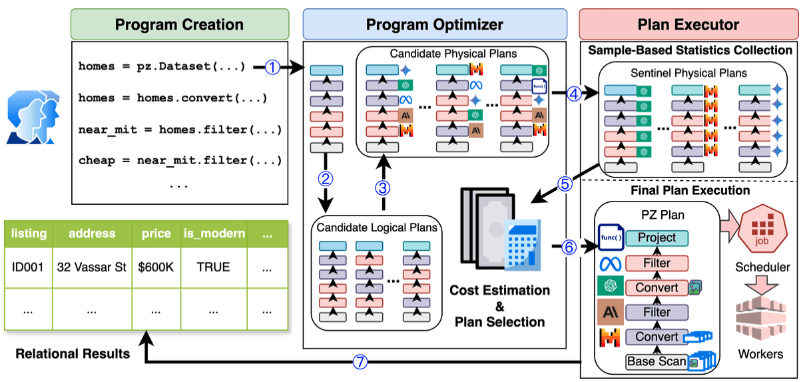
工作负载
通过描述了AI驱动的分析任务的工作负载(这些任务通常涉及传统数据处理与AI语义推理的交织)处理大量数据,并且可以分解为对数据对象集合的一系列操作。

优化方法
PALIMPZEST使用了一系列物理和逻辑优化方法,包括模型选择、代码合成、多数据提示处理和输入令牌减少等,以提高执行效率。

我们在法律文献、房地产搜索和医学模式匹配任务上评估了PALIMPZEST。我们展示了即使是我们的简单原型也提供了一系列吸引人的计划,包括一个比基线方法快3.3倍、便宜2.9倍的计划,同时也提供了更好的数据质量。
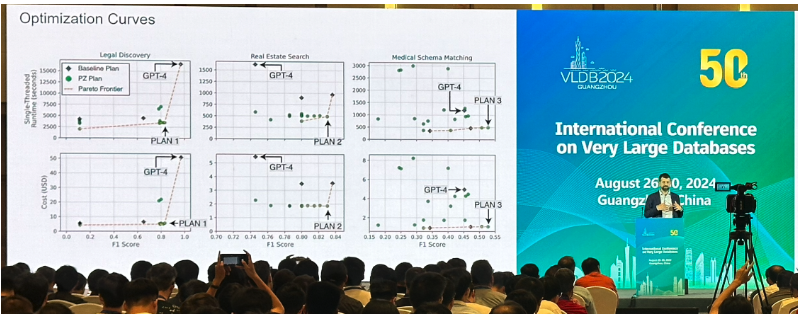
在启用并行处理的情况下,PALIMPZEST可以产生相对于单线程GPT-4基线的计划,速度提升高达90.3倍,成本降低9.1倍,同时获得的F1分数在基线以内83.5%。

未来,我们需要提高抽象层次,将AI编程从写代码的层面提升,以应对不断变化的AI模型、硬件和需求。

Samuel Madden是MIT计算机学院的杰出教授,领导MIT的数据系统小组和数据科学与人工智能实验室(DSAIL)。研究领域包括数据库、分布式计算和网络。研究项目包括学习型数据库系统、C-Store列式数据库系统和CarTel移动传感器网络系统。

数据库领域的持续发展离不开研究学者、从业者、开发者和用户的共同努力。作为本次VLDB会议赞助商之一,偶数一直专注于云数据平台、数据智能产品及解决方案。在数据领域深耕多年,自主研发分布式数据库OushuDB和实时湖仓数据平台Skylab。

