一次讲清楚实时湖仓数据处理架构如何落地!
数据驱动的世界,面对纷繁复杂的业务场景和海量数据处理的挑战,实时湖仓变得越来越流行,本文尝试一次讲清楚针对不同业务场景如何选择实时湖仓的数据处理架构。
要甄别和梳理常见的业务场景,我们可以先按照时效性区分业务场景,可以分为实时、准实时、离线。实时通常是秒级甚至毫秒级;准实时一般是分钟级;离线通常以天为单位。

然后,我们再按照数据分析与应用需求的灵活性进行划分,分为固定需求和灵活需求。固定需求通常以事件驱动或者固定的时间周期支持数据分析应用;灵活需求根据用户的随机、临时需求支持分析应用。
举例,我们每日、每周收到的固定报表就是一个典型的固定需求场景,我们看到的春晚直播大屏,以及双十一、618等大促活动的实时作战大屏甚至是都是固定需求,虽然他们是实时显示的,但是分析师或者业务运营负责人不会在活动当天临时更改大屏显示的数据指标,因为这些指标的计算逻辑都是提前制定好的。
相反,当我们发现了业务问题,想从客群或者业务流程上分析出原因,那么我们就需要灵活的去查询数据平台进而分析和发现业务问题。比如,为什么上周的订单量暴增?是什么人群购买的?是从直播间下单的还是收到了优惠券?诸如此类的随机的系列问题,大概率是不会在现有的固定报表中找到答案,尤其是用户想要立刻知道问题所在,离线的固定报表就更难支持,我们需要灵活的查询,甚至是实时、灵活的查询支持。
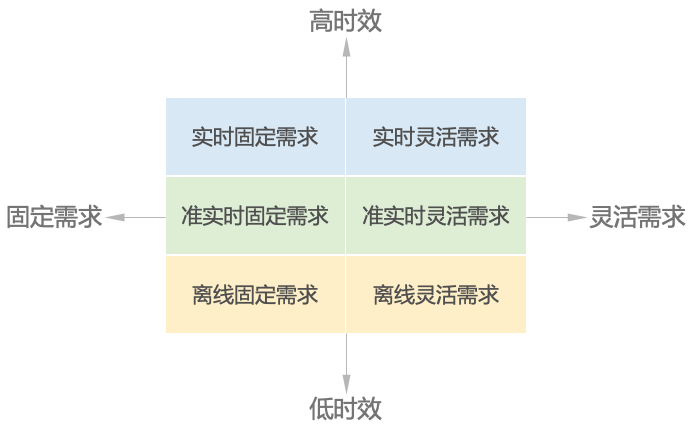
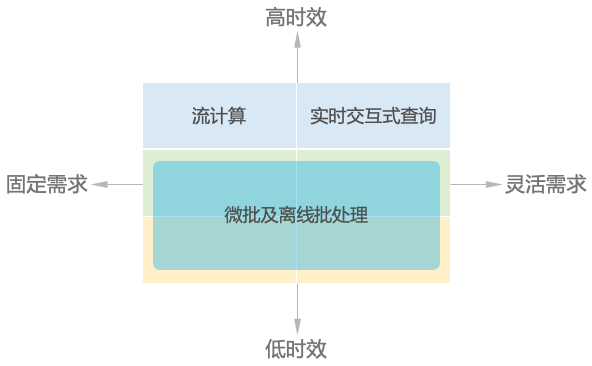
我们通过需求的灵活性与时效性两个维度,将业务场景简单的分为了六种,但是从技术架构的角度,其实只有三种,因为准实时和离线的可以使用同样的架构。于是,从技术角度我们可以将三种场景从技术角度划分为:流计算、实时交互式查询、微批及离线批处理。
为了能让大家了解不同场景的特点,我们尝试通过一个电商的案例进行讨论。该电商采用线下和线上电商结合的渠道方式,有不同的业务场景。

场景一
音频设备是该电商的优势品类,为了及时监控门店业务并快速做出决策,需要在实时大屏上呈现下列2个指标:
①近1小时,音频设备品类订单金额
②近1小时,音频设备品类订单数
场景二
19:00 - 22:00 是电商平台晚间黄金时段,假设现在2024年6月18日晚上20:15,从活动运营负责人处接到需求,需要查询当日19:00以来,线上App销售量Top3产品是哪些。得到结果后,运营人员想进一步了解性别、年龄、渠道、以及优惠券对Top 3产品销售量的影响,需要分别查询出Top3每一款产品的用户性别占比、年龄段占比、渠道占比、优惠券占比。
场景三
管理层需要每周定期查看近期的业务表现,通过一些较为复杂的核心业务指标,持续监控业务运营情况。
① 为了解消费者行为,识别高价值客户,需要查看每一天的平均订单金额;
②音频设备品类下的QC35无线降噪耳机是潜在热销产品,需要观察该产品每日的总销售量。
在了解不同数据架构的目标场景之前,我们就可以通过案例中的场景信息,凭直觉进行匹配。不难发现,这三个场景恰好对应流计算、实时交互式查询、微批及离线批处理三个不同的技术方案。
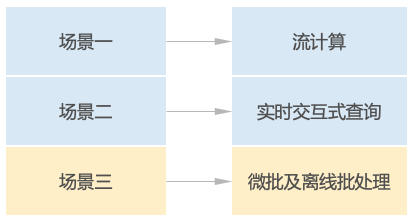
接下来我们看下不同方案的技术特点和适用场景。
流计算
适用场景:
流计算适用于需要快速响应事件的业务场景,如实时监控、实时推荐系统等事件驱动的系统。
特点:
低延迟:数据处理几乎无延迟,能够即时反映事件变化。
高吞吐量:能够处理大量数据流,适用于大规模数据环境。
实时交互式查询
适用场景:
实时交互式查询适用于需要快速获取数据并进行分析的业务场景,不以事件驱动,也不以固定周期定时驱动,而是根据应用或用户需要随时去查询。
特点:
灵活度高:可以按照需求灵活的、交互式的进行复杂查询和多维分析。
快速响应:能够快速回答用户查询。
离线批量处理
适用场景:
离线批量处理适用于不需要即时数据反馈的业务场景,如历史数据分析、数据仓库构建、大规模数据挖掘等。
特点:
成本效益:通常成本较低,适合处理大规模数据集。
稳定性:处理过程稳定,适合长时间运行的任务。
技术方案如何实现?
流计算
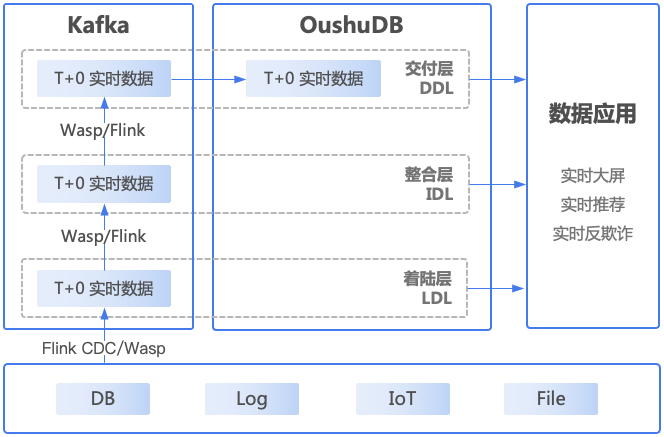
该架构通常需要依赖流计算引擎(如Flink)和消息中间件(如Kafka)做支撑,进行实时流计算,然后根据流计算的结果直接触发类似反欺诈提醒的业务逻辑,或者把流计算的结果写到数据库中(如OushuDB),供业务侧查询和使用。
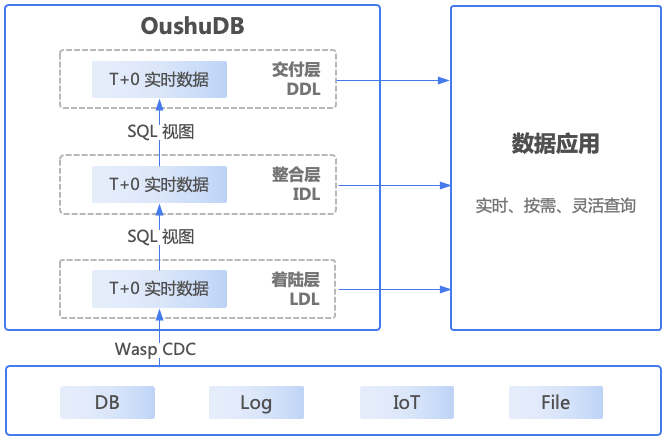
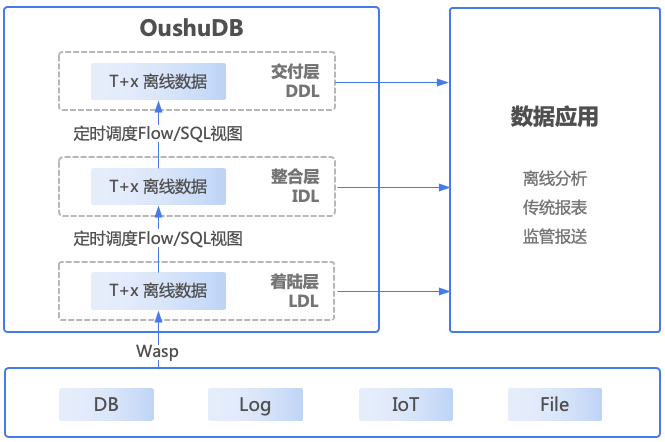
数据分层可以通过Flink或者偶数Wasp实现。在偶数的实时湖仓建设方法中,数据层可分为着陆层(Landing Data Layer)、整合层(Integration Data Layer)、交付层(Delivery Data Layer)三层。着陆层用来接入并暂存原始形态的数据以供后续处理,整合层需对原始形态数据进行重整、重组(可以基于不同数据建模方法,比如维度建模或者范式建模)并施加治理管制措施以达到长期数据资产管理要求,交付层则面向不同应用形式、场景模式的具体要求提供特定的数据消费服务。
实时交互式查询
在实时交互式查询场景中,数据同步工具通过CDC(Change Data Capture)把源数据更新到着陆层(LDL),这就要求数据平台能支持高性能的Update/Delete,当前的Hudi或者Iceberg在这方面性能有所欠缺,偶数的建设方法论中,使用偶数自研存储Magma,通过支持高性能Update/Delete,实现实时交互式查询场景。
微批及离线批处理
在该架构中,数据同步工具需要同时负责准实时/实时的数据,也需要负责离线批量的数据,这个对数据同步工具的要求略高。实时/准实时的数据同步到数据平台之后,再使用分钟级别的批量调度去做后续的数据处理,整体的数据处理的时延可以达到分钟级别,满足一些准实时的业务需求。
如何选择?
了解了不同方案的特点和实现方法,就可以根据业务场景选择合适的数据处理方式,在选择和搭建数据处理架构时,除了从业务需求的角度,还应考虑数据量、实时性要求、成本和兼容性等因素:
①业务需求:明确业务目标和需求,确定是否需要实时性、交互性或成本效益。
②数据量:评估数据规模,选择能够处理相应数据量的技术。
③实时性要求:确定业务是否需要实时数据处理。
④成本:考虑技术实施和运维的成本。
⑤兼容性:选择与现有技术栈兼容的解决方案。
能否兼得?
数据处理方案从设计到建设,因地制宜选择合适的架构固然重要,但是各种场景往往同时存在,可不可以采用一个整合的架构使微批及离线批处理、实时交互式查询、流计算同时落地?
答案是肯定的,这就是Omega架构。Omega架构是一种先进的数据处理架构,它能够统一处理实时流数据、实时交互式查询、微批及离线批处理多种数据处理需求,在不同数据层(着陆层、整合层、交付层)同步拉通数据并保证数据一致性,提供了一种灵活、高效、可扩展的解决方案,能够应对现代企业面临的复杂和多变的数据挑战。

Omega架构的优势和用户价值:
①全实时:该架构能够支持实时流处理、实时交互式查询、微批及离线批处理,满足固定需求和灵活需求,实现全实时数据处理,让用户快速响应市场和业务变化,并提供即时的数据分析和决策支持。
②数据一致:Omega架构巧妙的设计思路结合OushuDB极致产品性能,保证了T+0实时数据区,和T+x离线数据区的数据一致性,让数据不同场景的数据应用都能得到一致的查询分析结果。
③入库快:Omega架构设计结合偶数Wasp实现了高效的数据摄取,能够快速接收和处理来自各种数据源的大量数据。通过偶数在自研存储上的不断优化,Omega架构加快数据的写入速度,实现快速入库。
④简化架构:通过整合不同的数据处理技术,Omega架构提供了一个统一的数据平台,相比传统数据架构数十个组件配合,大大简化了整个数据处理流程,减少了系统的复杂性,从而降低了维护成本和操作难度。
⑤降低成本:通过减少对多个独立系统的依赖,Omega架构有助于降低总体拥有成本(Total Cost of Ownership)。
Omega架构通过整合多个数据处理技术,为企业提供了一个强大、灵活且高效的数据平台,面对流计算、实时交互式查询和离线批量处理等不同场景,选择Omega架构对企业而言是最优解,帮助企业在数据驱动的决策和运营中保持竞争力。

